Pereiti prie darbo be popieriaus yra puiki idėja, tačiau tai nėra vien tik spausdinimo atsisakymas. Esmė ta, kad dokumentai skirti žmonėms skaityti, o kompiuteriai apdoroja duomenis. Daugumoje dokumentų apdorojimo scenarijų fizinį popierių pakeitėme į dvejetainį ekvivalentą (dažniausiai matomą kaip PDF – Portable Document Format), ir tai tinkama dalykams, kuriuos skaito žmonės: knygoms, žurnalams, brošiūroms ir pan. Tačiau tai nėra gerai automatizuotiems darbo procesams.
Programinės įrangos robotai neskaito, jie vykdo.
Pamatysime, kaip jie veikia su UiPath Document Understanding.
Žala jau padaryta.
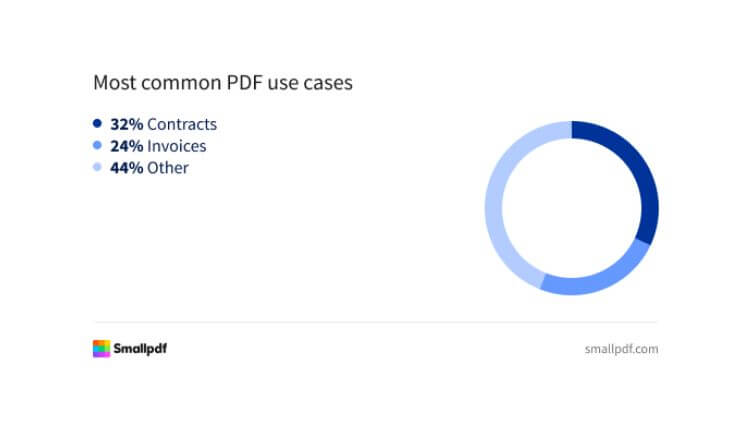
Jei dirbate biure, tikėtina, kad jau esate susidūrę su skaitmeniniais dokumentais. Nereikia giliai kapstytis statistikoje, kad pajustumėte jų buvimą, tačiau pažiūrėkime, ką apie PDF naudojimą sako internetas.

Šie skaičiai yra gana abstraktūs. Tas pats tinklalapis praneša, kad PDF kūrimas nuo 2020 metų kasmet auga maždaug 12 %. Jie yra visur, ir jūsų verslas beveik neabejotinai gauna sąskaitas faktūras, pirkimo užsakymus arba sutartis šiuo formatu.
Turėtume džiaugtis dėl išsaugotų medžių, mažiau atliekų ir standartizuoto formato (ISO 32000), tačiau iš verslo automatizavimo perspektyvos tai buvo tarsi įvartis į savo vartus. Skaičiai rodo, kad PDF niekur nedings, bet užuot pasyviai priešinusis, pakalbėkime apie tai, kaip automatizuoti jų kūrimą patiems.
Kokia tavo problema?
Trumpai tariant, mes sukūrėme formatą žmonių akims, o dabar tikimės, kad kompiuteriai jį apdoros. Ilgesnei versijai pereikime per tipišką pavyzdį, kai sąskaitos faktūros apdorojamos kaip gaunami failai, pvz., el. laiškų priedai.

Žmogaus įsitraukimas yra aiškiai apibrėžtas: kažkas „Design Studio“ parengia sąskaitą faktūrą, geriausia naudodamas ERP sistemą arba kokią nors programą, ir ją išsiunčia. Kitoje pusėje kažkas „ABC Corporation“ gauna failą ir rankiniu būdu suveda atitinkamus duomenis į savo ERP sistemą tolesniam apdorojimui. Paprastai lengva perskaityti pagrindinę informaciją, pavyzdžiui, bendrą sumą.
Vis dėlto procesas yra pasikartojantis, linkęs į klaidas ir užimantis daug laiko. Būtų gerokai paprasčiau, jei abi pusės sutiktų keistis struktūruotais duomenimis per tinkamą sąsają, tokią kaip Electronic Data Interchange (EDI). Deja, mūsų patirtimi tai vis dar labiau išimtis nei taisyklė.
Didesnės iniciatyvos, tokios kaip nacionalinės e. sąskaitų faktūrų sistemos, yra žingsnis teisinga kryptimi, tačiau sąskaitos faktūros yra tik ledkalnio viršūnė. Verslai kasdien remiasi daugybe skirtingų dokumentų tipų: pirkimo užsakymais, pristatymo kvitais, važtaraščiais, CE sertifikatais… sąrašas tęsiasi.
Rasti stebuklingą sprendimą
Iš programinės įrangos robotų perspektyvos viskas greitai tampa sudėtinga. Kompiuteris nesupranta, ką reiškia „sąskaitos data“ (etiketė), ir prieš iš tikrųjų panaudodami tą reikšmę turime atlikti kelis papildomus veiksmus.
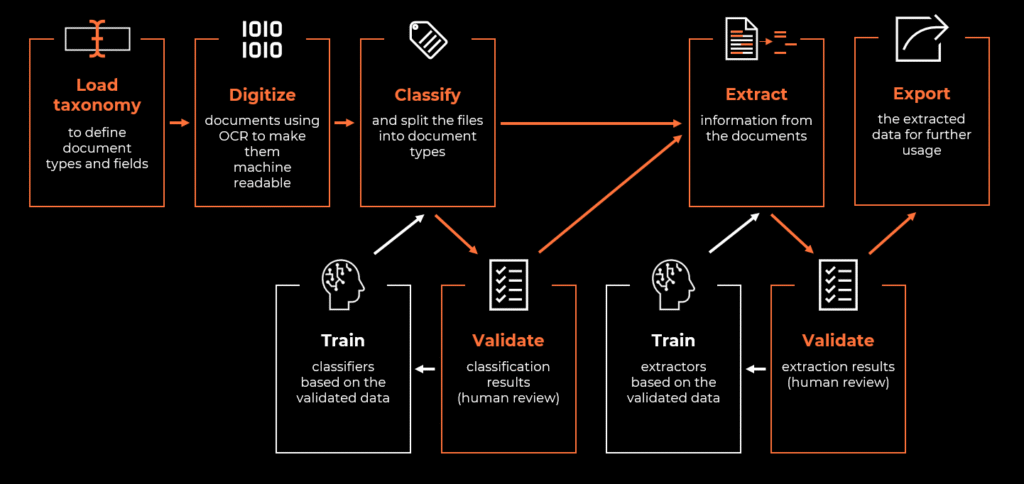
Čia ir žengiame į Intelligent Document Processing (IDP) pasaulį – technologiją, kuri naudoja dirbtinį intelektą (AI), kad automatizuotų įvairių tipų dokumentų duomenų klasifikavimą, ištraukimą ir apdorojimą. Ji sujungia tokias technologijas kaip mašininis mokymasis, natūralios kalbos apdorojimas (NLP) ir optinis simbolių atpažinimas (OCR). Konkreti sistema ar sprendimo tiekėjas yra pasirinkimo reikalas, tačiau šiame straipsnyje mes susitelksime į UiPath Document Understanding™ ir nuosekliai išskaidysime dokumentų apdorojimo procesą žingsnis po žingsnio.
Taigi pasakyk man, ko tu nori.
Tinkama pradinė analizė yra labai svarbi bet kokiai automatizacijai, tačiau išmaniojo dokumentų apdorojimo projekte ji yra visiškai būtina.
Populiaru ne be priežasties.
Pirmiausia turime apibrėžti, kokie dokumentų tipai turėtų patekti į apimtį. Iš techninės pusės tai galėtų būti bet kurie, todėl tokie tipiški pelningumo rodikliai kaip apdorojamų dokumentų kiekis, sugaištas laikas (FTE) ar žmogaus klaidos tikrai padės susiaurinti pasirinkimą. Tai tvirtas pagrindas, tačiau automatizuojant dokumentų darbo eigas reikia atsižvelgti ir į daugiau dalykų.
Dokumentų paplitimas yra geras rodiklis. Ne tik turinys yra aiškiai apibrėžtas (pvz., informacija, kuri turi būti pateikta sąskaitose faktūrose, gali būti reglamentuojama vietos įstatymų), bet ir kai kurie tiekėjai siūlo iš anksto apmokytus mašininio mokymosi modelius populiariausiems dokumentų tipams. Būtent taip yra su UiPath Document Understanding™ sistema ir jos paruoštais naudoti iš anksto apmokytais paketais. Jei jūsų dokumento tipui yra atitinkamas paketas – naudokite jį – jis suteiks projektui pradines klasifikavimo ir ištraukimo efektyvumo galimybes (apie tai vėliau), nereikalaujant kurti savo mašininio mokymosi modelio.
Skirtingi sąskaitos faktūros atspalviai
Net jei turime tik kelis dokumentų tipus, galime susidurti su daugybe skirtingų išdėstymų. Mūsų pavyzdyje kiekviena organizacija, išrašanti mums sąskaitą, gali turėti savo formatavimą, lentelių schemą, antraštės vietą, poraštę (arba jos neturėti) ir taip toliau. Tai nuveda mus prie neformalios dokumentų klasifikacijos į 3 grupes: struktūruotus, pusiau struktūruotus ir nestruktūruotus dokumentus.
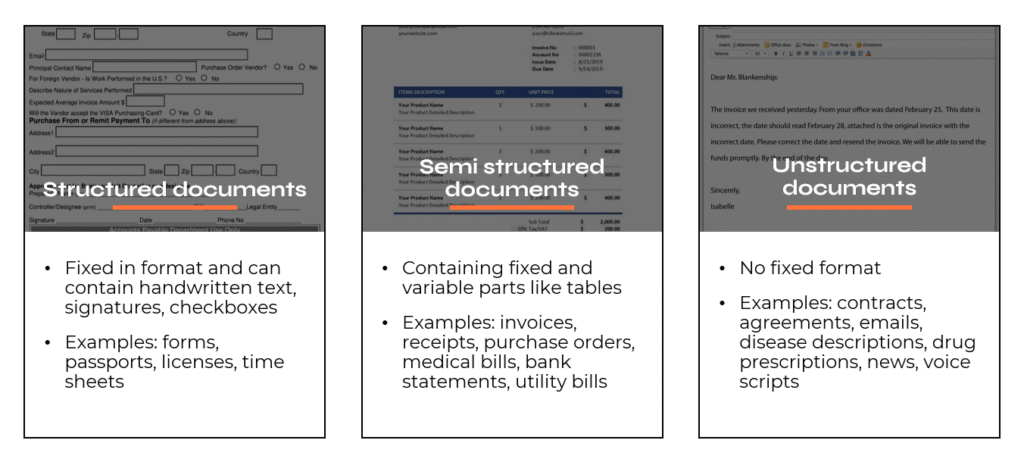
Ankstesnės kartos dokumentų apdorojimo įrankiai stipriai priklausė nuo išdėstymų, kur kiekvienas iš esmės buvo „kietai“ užkoduotas kaip trafaretas, pvz.: surasti žodį ir pajudėti viena pozicija į dešinę, kad gautum reikšmę. Šis metodas yra labai jautrus pokyčiams ir reikalauja nuolatinės stebėsenos bei priežiūros.
Gera žinia ta, kad modernios sistemos, tokios kaip UiPath Document Understanding™, yra nepriklausomos nuo išdėstymo, todėl gavus anksčiau nematytą dokumentą jis turėtų būti apdorojamas panašiu tikslumu (kelių procentų nuokrypis) ir neturėtų sugadinti darbo eigos. Vis dėlto turime labai atidžiai stebėti išdėstymus ir kruopščiai juos analizuoti prieš kuriant dokumentų apdorojimo automatizavimą. Išdėstymai gali būti labai kūrybiški, kas malonu žmogaus akiai, bet kompiuteriui gali tapti tikru galvosūkiu.
Pagrindinė informacija
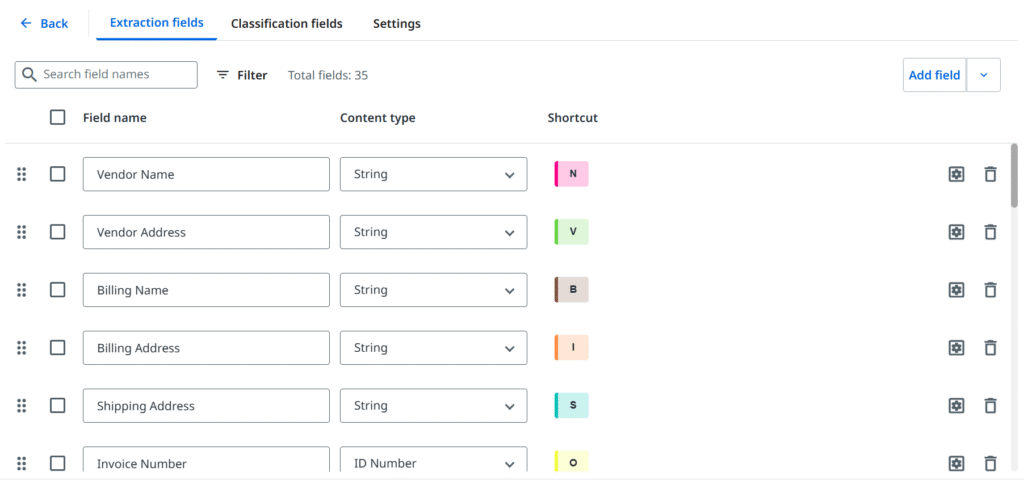
Atsižvelgiant į tai, kas buvo aprašyta aukščiau, pagaliau atėjo laikas apibrėžti laukus, kurie iš esmės yra informacijos dalys, kurias norime išgauti iš dokumento. Vėlgi, dažniausiai pasitaikantys laukai dažnai jau būna iš anksto paruoštuose paketuose, ir verta pasinaudoti tuo pradiniu efektyvumu, tačiau jūsų verslo poreikiai nulems galutinį tikslinį rinkinį.
– Dokumentų tipų tvarkyklė
Daugumoje scenarijų nurodome dvi išgaunamų duomenų grupes. Pirma, bendrieji (antraštės lygmens) laukai, kurie paprastai dokumente pasirodo vieną kartą ir yra vienos reikšmės (nors ne visada), pavyzdžiui: sąskaitos numeris, data arba bendra suma. Tuomet daugelis dokumentų turi eilučių ir stulpelių struktūrą, kuri puikiai tinka lentelės laukams – sukuriame antraštes ir galime apdoroti neribotą eilučių skaičių, net jei jos tęsiasi per kelis puslapius. Su lentelėmis patogu dirbti, tačiau (vėlgi) išdėstymai gali būti pernelyg sudėtingi: persidengiančios langelių reikšmės, eilutės, atskirtos kitu turiniu, arba (atsargiai!) įdėtosios lentelės – joms gali prireikti kitokio požiūrio arba pažangesnių technikų.
Kai kurios sistemos taip pat gali pasiūlyti papildomas funkcijas, tokias kaip reikšmių postapdorojimo metodai arba skirtingi algoritmai atitikčių vertinimui. Verta paminėti, kad UiPath Document Understanding™ suteikia papildomų klasifikavimo laukų (nereikėtų jų painioti su dokumento tipu). Jie gali būti naudingi, jei norime įvesti detalesnį suskirstymą ir kategorizuoti dokumentus pagal valiutą, kalbą, potipį (pvz., kreditinę sąskaitą) ir pan.
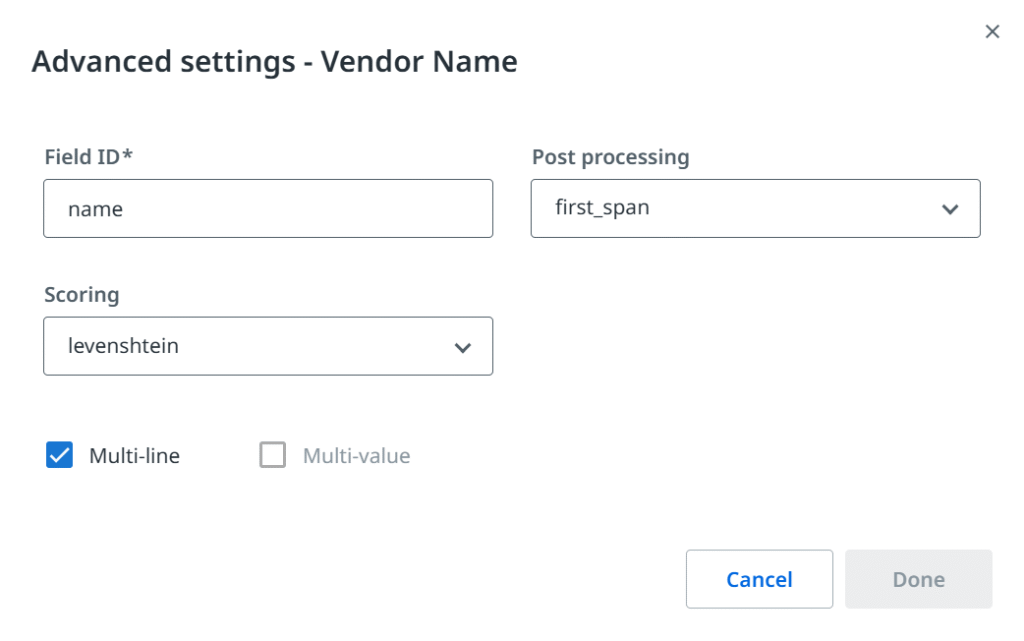
Visi šie pagrindiniai elementai – dokumentų tipai ir laukai – apibrėžia mūsų dokumentų apdorojimo projektą ir dažnai vadinami taksonomija. Prieš pradėdami ją naudoti, turime išspręsti dar vieną žmonių ir kompiuterių skirtumą: matymą.
Leisk jam matyti tai, ką matai tu.
Kompiuteriai puikiai susidoroja su tekstu – tol, kol jis iš tikrųjų yra dokumente. Iš Word ar Excel sugeneruotas PDF dažniausiai turi tikrą, pažymimą tekstą. Tačiau ne kiekvienas dokumentas yra toks (dažnai vadinamas „natūraliu“). Daugelyje verslo atvejų vis dar tenka dirbti su nuskenuotais dokumentais, kurie iš esmės yra tik vaizdai.
Čia IDP sistema ir turėtų apimti failų skaitmeninimą. Šis procesas paprastai reiškia fizinio popieriaus pavertimą elektroniniu formatu. Mūsų gaunami failai jau yra skaitmeniniai, todėl šiame kontekste tai reiškia teksto išgavimą iš nuskenuotų dokumentų ar vaizdų, naudojant anksčiau minėtas optinio simbolių atpažinimo technologijas.
Siekiant paprastumo, laikykime, kad failų skaitmeninimas apima abu šiuos aspektus. Gera žinia ta, kad spausdinimas ir skenavimas darosi vis retesni, o šiandienos OCR varikliai yra gerokai efektyvesni nei prieš kelerius metus.
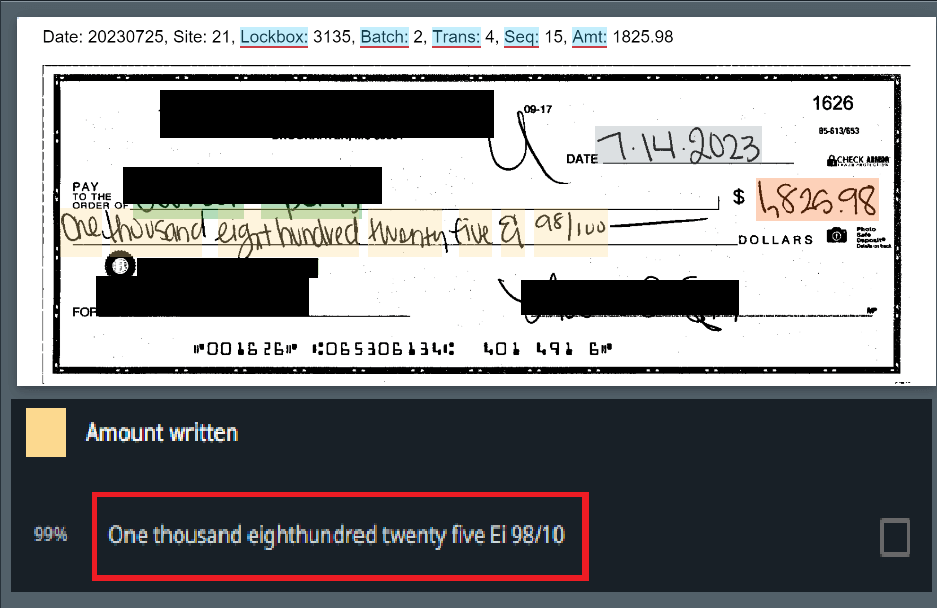
Vis dėlto būkite atidūs dėl įvesties duomenų, kuriuos ketinate apdoroti. Prastos kokybės nuskenuoti dokumentai arba tie, kuriuose gausu ranka rašytų pastabų, gali tapti rimtu iššūkiu net ir galingiausioms OCR sistemoms ir potencialiai sužlugdyti jūsų automatizavimo projektą dar jam neprasidėjus.
Daiktų sudėjimas į dėžutes
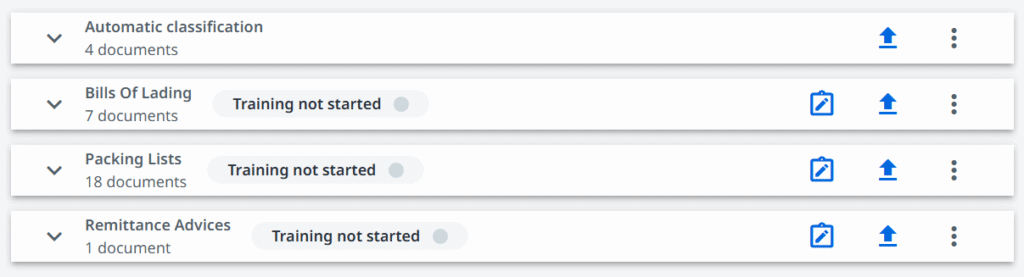
Tvarkos palaikymas visada buvo svarbus, nesvarbu, ar popierius yra fizinis, ar skaitmeninis. Įvairių gaunamų dokumentų rūšiavimas gali skambėti kaip smulkmena, tačiau jis gali ženkliai supaprastinti mūsų procesus, ypač esant dideliems apimtims.
Išmaniojo dokumentų apdorojimo srityje rūšiavimas į grupes vadinamas klasifikavimu. Tikslas paprastas: priversti kompiuterį atpažinti, kokio tipo dokumentas tai yra, tačiau būdai tam pasiekti yra įdomi tema.
Yra keli metodai, besiskiriantys sudėtingumu. Pirmos mintys dažniausiai nuveda prie raktažodžiais paremtų metodų. Ieškome specifinių ir pasikartojančių frazių, pavyzdžiui, tikimės, kad dokumente bent kartą ar net kelis kartus pasirodys žodis „invoice“. Šis metodas neapsiriboja tik konkrečių žodžių užkodavimu – galime ieškoti ir raštų, pavyzdžiui, nuoseklių raidžių ir skaičių kombinacijų, kur praverčia reguliariosios išraiškos. Jų neaiškinsiu, nes jos lengvai galėtų užpildyti atskirą straipsnį.
Realiuose atvejuose viskas paprastai būna sudėtingiau. Raktažodžiai pasirodo nereguliariai arba sutampa tarp dokumentų tipų, kai kurie žodžiai yra svarbesni už kitus. Norint spręsti šias problemas, UiPath Document Understanding™ sistema siūlo pažangius, dirbtiniu intelektu patobulintus klasifikatorius.
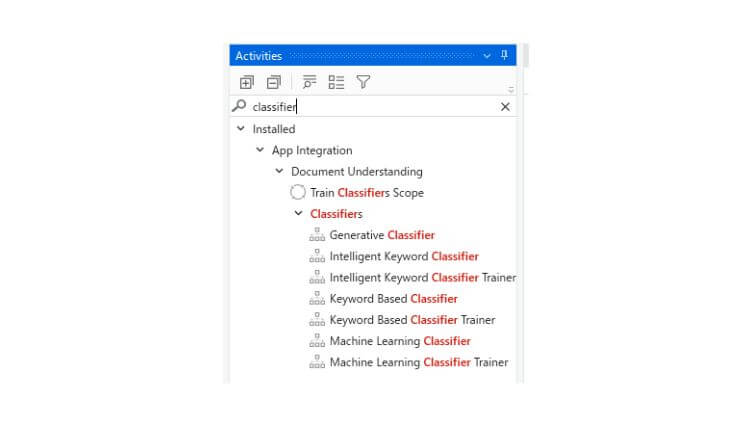
Turime galimybę sukurti savo specialų mašininio mokymosi klasifikatorių, kuris yra apmokomas mūsų dokumentais. Tikslūs požymiai ir architektūra, naudojami kuriant modelį, nėra žinomi (intelektinė nuosavybė), tačiau trumpai tariant, algoritmas išmoksta išskirtinių raštų iš pateiktų pavyzdžių. Document Understanding™ supaprastina mokymą, kurį aptarsime vėliau šiame straipsnyje.
Kita parinktis yra išmanusis raktažodžių klasifikatorius, kuriame variklis pats pasirenka žodžius ir priskiria jiems svorius. Tai paprastai konfigūruojamas, tačiau gana visapusiškas sprendimas, kuris papildomai gali atskirti kelis dokumentus, sujungtus į vieną failą.
Galiausiai, kaip galima tikėtis iš dabartinio genAI pakilimo, yra ir galimybė leisti didžiajam kalbos modeliui atlikti sunkiausią darbą. Galime rinktis iš įvairių LLM, o konfigūravimas iš esmės susiveda į veiksmingų klasifikavimo komandų parengimą.
Informacijos išgavimas
Taksonomija apibrėžia, kurių laukų mums reikia, ir dabar pagaliau atėjo metas išgauti duomenis. UiPath Document Understanding™ sistemos ištraukikliai veikia pagal panašų principą kaip ir klasifikatoriai: nuo paprasto, raktažodžiais paremto duomenų išgavimo iki galingų mašininio mokymosi ir genAI galimybių. Išgavimo konfigūravimas beveik nepastebimas – komponentai išgauna tą informaciją, kurią nurodėme taksonomijoje, ir grąžina reikšmes, priskirtas sukurtiems kintamiesiems. Paprasta.

Šiek tiek sudėtingiau gali būti teisingai numatyti ir priskirti duomenų tipus kartu su papildomomis parinktimis, pvz., leisti laukui būti kelių eilučių (pvz., adresai) arba kelių reikšmių (pvz., el. pašto adresai). Galime nustatyti kiekvieną lauką kaip eilutės (string) tipą, tačiau modelis gali veikti geriau, jei leisime jam ieškoti „piniginės sumos“ ir automatiškai konvertuoti reikšmę.
Laukų apibrėžimai taip pat atlieka svarbų vaidmenį: užsakymo data ir pristatymo data abu pateikiami datos formatu, tačiau jie reiškia du skirtingus informacijos elementus. Papildomas laikas, skirtas kruopščiai kurti taksonomiją, turėtų atsipirkti efektyviu ir tiksliu duomenų išgavimu.
Nuo prognozės iki patvirtinimo
Dabar jau žinome apie klasifikavimą ir išgavimą ir tai, kad išmanusis dokumentų apdorojimas nėra nei magija, nei spėliojimas.
Vis dėlto net ir pažangiausi bei pakankamai apmokyti modeliai daro klaidų. Bet kokia dirbtiniu intelektu paremta automatizacija niekada nebus 100% tiksli, kai testinis pavyzdys yra pakankamai didelis, kad sėkmė nebeturėtų įtakos rezultatui. Klaidos rodiklis vis tiek gali būti mažesnis nei apdorojant rankiniu būdu (ypač esant didelėms apimtims), tačiau tiksliniai skaičiai priklausys nuo konkretaus verslo atvejo.
Toliau pereinant, pagrindinis klausimas yra tai, kaip tvarkyti modelio klaidas. UiPath Document Understanding™ sistema įveda pasitikėjimo lygio sąvoką, išreiškiamą procentine reikšme. Jis dažnai painiojamas su tikimybe, tačiau iš tiesų atspindi modelio užtikrintumą, kad grąžintas klasifikavimo arba išgavimo rezultatas yra teisingas atsakymas, atsižvelgiant į visą kontekstą, tokį kaip OCR efektyvumas, vieta, lauko apibrėžimas ir pan.
Turėdami 0–100 % reikšmę kiekvienam klasifikavimo ir išgavimo rezultatui (kiekvienam laukui atskirai), lengvai galime įsivaizduoti scenarijų, kuriame nustatome priimtinas ribas, pvz.: viską, kas siekia 90 % ir daugiau, laikome teisingu. Vėlgi, reikšmės labai priklausys nuo verslo atvejo, kuriame klaidos poveikis atlieka reikšmingą vaidmenį. Atminkite paklausti savęs, kas gali nutikti, jei modelis yra 90 % užtikrintas, tačiau duomenys iš tikrųjų neteisingi.
Ką daryti, jei rezultatas nepatenka į nustatytą ribą? Viena strategija būtų įtraukti žmogaus patvirtinimą. Kai dirbtinis intelektas nėra pakankamai užtikrintas – tai dar nereiškia, kad jis klydo – leidžiame tikram žmogui peržiūrėti ir patikrinti rezultatą. Document Understanding™ siūlo paruoštas naudoti integruotas programas (Actions ir Apps), iš kurių bet kuri gali veikti kaip patvirtinimo stotis. Iš esmės funkcionalumas susiveda į paprastą interaktyvią formą, kurioje vartotojai mato dokumentą ir automatizuoto dokumentų apdorojimo rezultatus. Pateikus formą, patvirtinti duomenys siunčiami toliau proceso eiga.
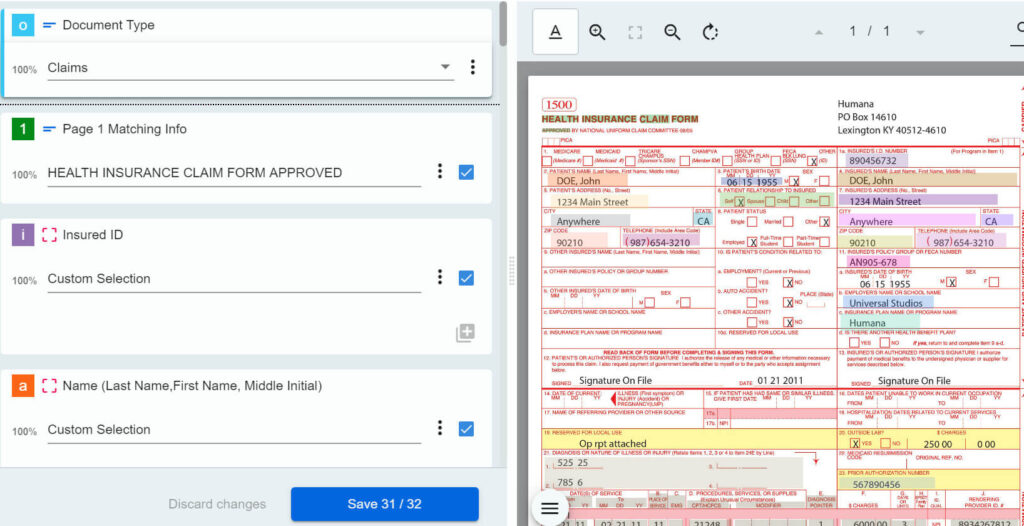
Pasitikėjimo lygis yra itin naudinga funkcija, leidžianti mums valdyti darbo eigą atsižvelgiant į apdorojimo aplinkybes ir rizikos veiksnius. Tačiau dar galingiau jį derinti su taisyklėmis pagrįstomis validacijomis: jei bet kurie išgauti duomenys turi atitikmenį mūsų sistemose, galime palyginti abi reikšmes ir valdyti procesą remdamiesi tuo rezultatu.
Treniruokite silikonines smegenis
Kadangi įdėjome tiek darbo peržiūrėdami klasifikavimą ir išgautų duomenų patvirtinimą, būtų gaila tuo nepasinaudoti. Kai kurios sistemos, įskaitant UiPath Document Understanding™, siūlo būdą užfiksuoti patvirtintus duomenis ir pakartotinai juos panaudoti kaip mokymo pavyzdžius tolimesniam modelio mokymui. Taip mūsų modelis laikui bėgant gali tobulėti.
Yra ir dar viena stadija, kurioje norime arba net privalome apmokyti modelį. Paruošti paketai veikia gana gerai, tačiau jei norime pagerinti iš anksto apmokyto įgūdžio efektyvumą, galime iškart pradėti projektą nuo žymėjimo sesijos. Tas pats taikoma ir pasirinktiniams dokumentų tipams – tai tarsi darbas nuo švaraus lapo, todėl be konkrečios taksonomijos apibrėžimo taip pat turime apmokyti ir pasirinktą modelį.
Laimei, pateikti mašininio mokymosi modeliams pavyzdžius yra labai paprasta. Sąsaja yra itin patogi vartotojui ir iš esmės susiveda į teisingų reikšmių patvirtinimą arba pasirinkimą puslapiuose pagal mūsų taksonomiją. Tai tarsi paspaudimų principu veikianti spalvinimo knygelė.
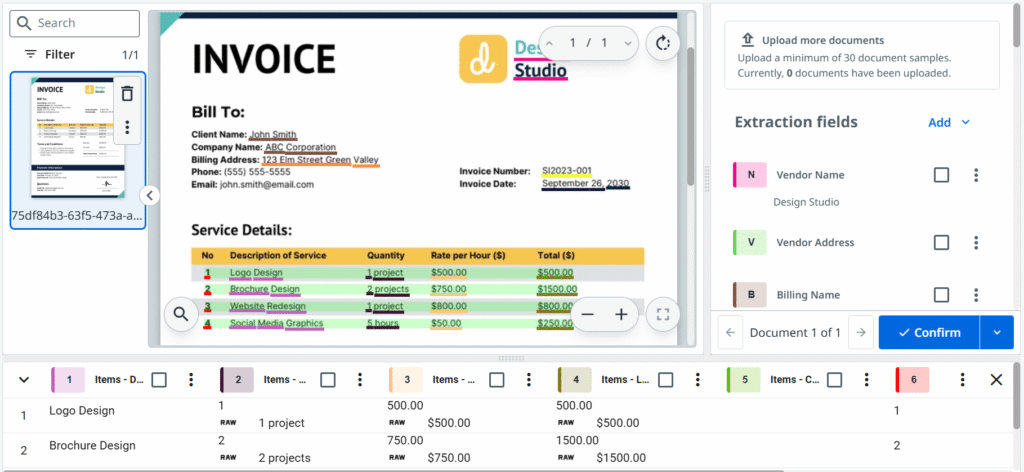
Grįžtant prie žmogaus grįžtamojo ryšio panaudojimo, galima pasiekti visiškai automatinį pakartotinio mokymo ciklą, tačiau yra bent dvi svarbios pastabos. Pirma, darome prielaidą, kad duomenys, gaunami iš patvirtinimo stoties, iš tiesų yra teisingi. Išgautų duomenų tikrinimo klaidos yra mažiau tikėtinos, bet vis tiek galimos. Antra, patvirtinimo stotyje reikia patvirtinti tik vieną reikšmę, o modelio mokymo pavyzdžiuose turi būti nurodytos visos konkretaus lauko reikšmės. Praktikoje tai reiškia, kad nepakitę kaip mokymo pavyzdžiai gali būti pakartotinai naudojami tik vieno puslapio dokumentai.
Apskritai geriausia praktika yra visada peržiūrėti pavyzdį prieš naudojant jį mokymui.
Pagrindinis tikslas
Mes pasiekėme laimingą pabaigą – apdorojame failus su įvairiomis dokumentų struktūromis, klasifikuojame kelis dokumentų tipus ir išgauname duomenis su patvirtinimu bei išimčių tvarkymu. Pagaliau atėjo laikas panaudoti rezultatus tiksliniame procese – juk visa tai darėme tam, kad galėtume realiai atlikti veiksmus su didžiuliais kiekiais gaunamų dokumentų.
Naudojant UiPath Document Understanding™ sistemą tereikia pasitelkti paruoštas veiklas, kurios patiekia duomenis tarsi ant sidabrinės lėkštės. Tiems, kurie nori naudoti Document Understanding™ modelius, bet likusią sprendimo dalį kurti kita technologija, siūlomas patogus API (daugiau – UiPath dokumentacijoje). Klasifikavimas ir duomenų išgavimas apima daugumą dokumentų apdorojimo scenarijų, kuriuos galima rasti bet kurios organizacijos verslo operacijose: pagalvojus, šių dviejų funkcijų visiškai pakanka.
Sąskaitų faktūrų apdorojimas yra tik vienas pavyzdys vienos darbo eigos, kurioje skaitmeninis popierius tėra nelaimingas informacijos nešėjas, kurią reikia perduoti tarp dviejų sistemų. Tokie įrankiai kaip UiPath Document Understanding™ puikiai sprendžia automatizavimo problemą, kai duomenys įkalinti PDF failuose ar skenuose.
Jeigu tik galėtume rasti alternatyvą tokio tipo failų siuntimui vieni kitiems.
O, palauk…




