Going paperless is a great idea, but there’s more to it than just not printing. The point is that documents are for humans to read whereas computers process data. In most document processing scenarios we changed physical paper into a binary equivalent (most often seen as PDFs – Portable Document Format), which is fine for things people read: books, magazines, brochures and the like. However, it’s bad for automated workflows.
Software robots don’t read, they run.
We’ll see how they run with UiPath Document Understanding.
The damage is already done
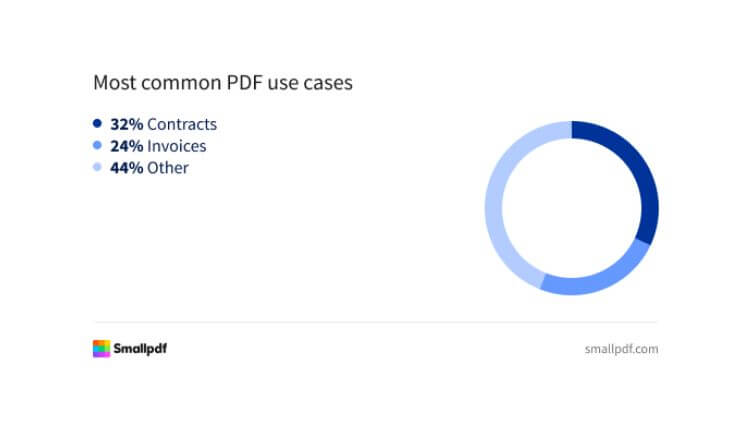
If you work in an office, chances are you’ve dealt with digital documents before. No need to dig deep into stats to feel their presence, but let’s see what the internet says about PDF usage.

Those numbers are quite abstract. The same website reports that PDF creation has been growing at about 12% per year since 2020. They’re everywhere, and your business almost certainly receives invoices, purchase orders, or contracts in this format.
We should be happy about saving trees and less waste or standardized format (ISO 32000), but from a business automation standpoint, it was a bit of an own goal. Numbers suggest PDFs aren’t going away, but instead of passive resistance, let’s talk about how to automate our own creation.
What is your problem?
In short, we designed the format for human eyes and now we expect computers to process it. For the long version let’s walk through a typical example of processing invoices as incoming files, e.g. as email attachments.

Human involvement is well defined: someone at “Design Studio” creates an invoice, ideally using an ERP system or some application and sends it over. On the other end, someone at “ABC Corporation” receives the file and manually types the relevant data into their own ERP system for further processing. It’s usually easy to read key information like total amount.
Nevertheless, the process is repetitive, error-prone and time-consuming. It would be far simpler if both sides agreed to exchange structured data through a proper interface like Electronic Data Interchange (EDI). Unfortunately, in our experience, that’s still more the exception than the rule.
Larger initiatives like national e-invoicing systems are a step in the right direction, but invoices are just the tip of the iceberg. Businesses rely on multiple document types every single day: purchase orders, delivery notes, bills of lading, CE certificates… the list goes on.
Finding the silver bullet
From a software robots perspective, things get tricky fast. A computer doesn’t understand what an “invoice date” (label) means and there are some extra steps involved before we can actually use that value.
This is where we step into the world of Intelligent Document Processing (IDP) – a technology that uses artificial intelligence (AI) to automate the classification, extraction and processing of data from various types of documents. It combines technologies like machine learning, natural language processing (NLP) and optical character recognition (OCR). A particular framework or solution vendor is a matter of preference, but for this article we’ll zoom in on UiPath Document Understanding™ and break down the document processing pipeline step by step.
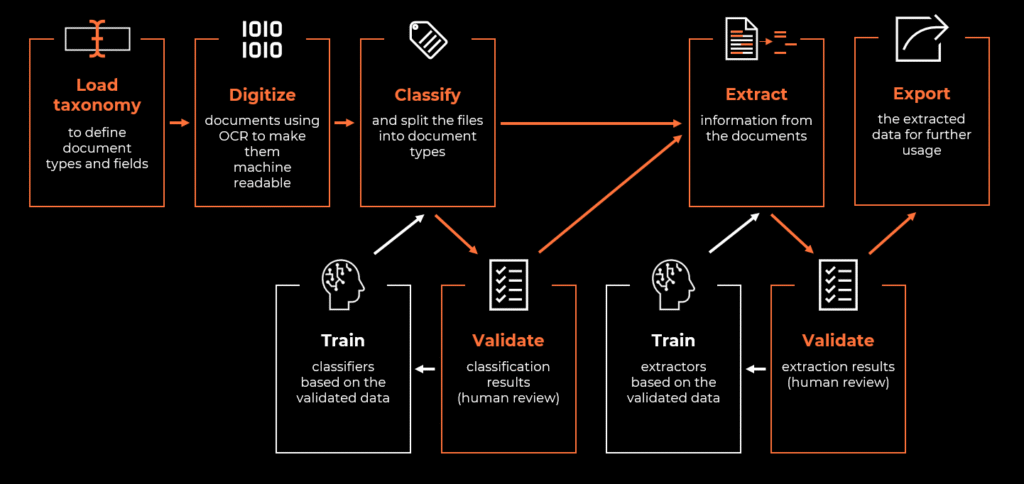
So tell me what you want
Proper initial analysis is crucial for any automation, but in an intelligent document processing project it’s absolutely essential.
Popular for a reason
First, we need to define what document types should fall into scope. Technically it could be any, so typical profitability metrics like processed volume, time spent (FTE) or human error will surely help to narrow the choice down. These are solid foundations, but there’s more to consider when automating document workflows.
Document commonness is a good indicator. Not only are the contents well defined (e.g. information required on invoices may be regulated by local law), but some vendors offer pre-trained machine learning models for most popular document types. That is exactly the case with the UiPath Document Understanding™ framework and its Out-of-the-box pre-trained packages. If your document type has a corresponding package – use it – it will kick start your project with base efficiency for classification and extraction (more on that later) without need to build your own machine learning model.
Different shades of invoice
Even if we have just a few document types, we could be facing multiple layouts. In our example, each organization invoicing us can have their own formatting, table scheme, header location, footer (or lack thereof) and so on. This brings us to informal division into 3 groups: structured, semi structured and unstructured documents.
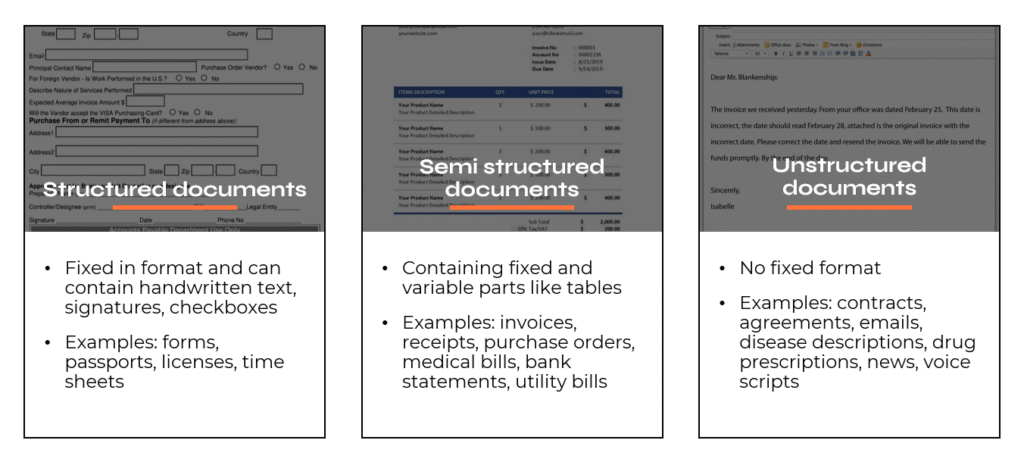
The previous generation of document processing tools heavily depended on layouts, where each was basically hardcoded as a stencil, e.g.: locate a word and move one position to the right to get a value. This approach is very prone to changes and requires constant monitoring and maintenance.
Good news is, modern frameworks like UiPath Document Understanding™ are layout independent so when we get previously unseen document it should be handled with similar accuracy (a couple of percent deviation) and it shouldn’t break the workflow. Nevertheless, we should pay close attention to layouts and carefully analyze them before building a document processing automation. Layouts can get very creative which may please the human eye, but can be a hard nut to crack for a computer.
The key information
Keeping in mind what’s been described above, it is finally time to define fields, which are essentially pieces of information that we want to extract from the document. Again, most common ones can be often found in pre-trained packages, and it’s worth using that base efficiency, but your business case will determine the target set.
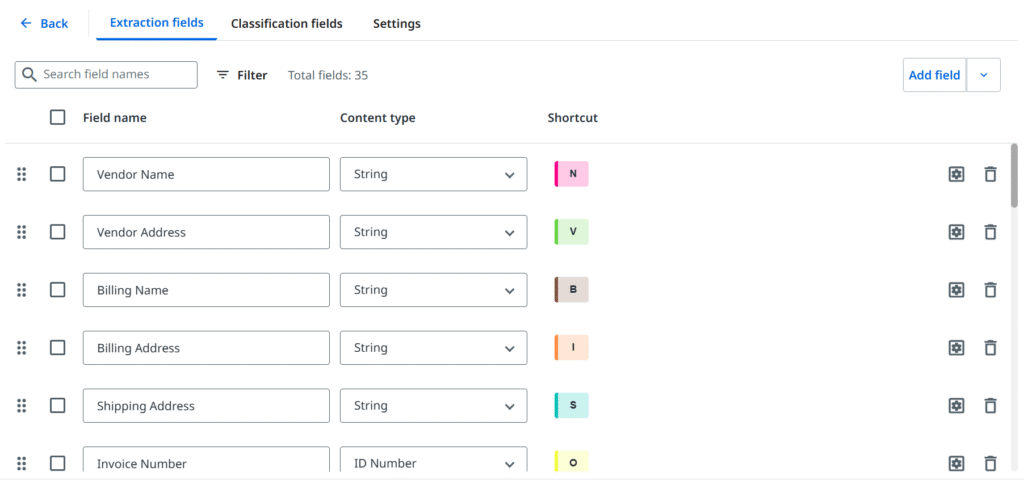
– Document type manager
In most scenarios, we specify two groups of extracted data. First, general (header-level) fields, which usually occur on a single page once and are single-value (not always), for example: invoice number, date, or total amount. Then, many documents will contain rows and columns structure which is a perfect fit for table fields, where we create the header and are good to go for an indefinite number of rows, even spanning through multiple pages. Tables are convenient to work with, but (again) layouts can get overly complex with overlapping cell values, rows separated with other content, or, (watch out!) nested tables – those might require different approaches or more advanced techniques.
Some frameworks may also introduce extra features like values’ post processing methods or different algorithms for match scoring. It’s worth mentioning that UiPath Document Understanding™ brings in additional classification fields (not to be confused with document type). These can be useful when we want to introduce a further division and categorize documents based on currency, language, sub-type (e.g. credit note), etc.
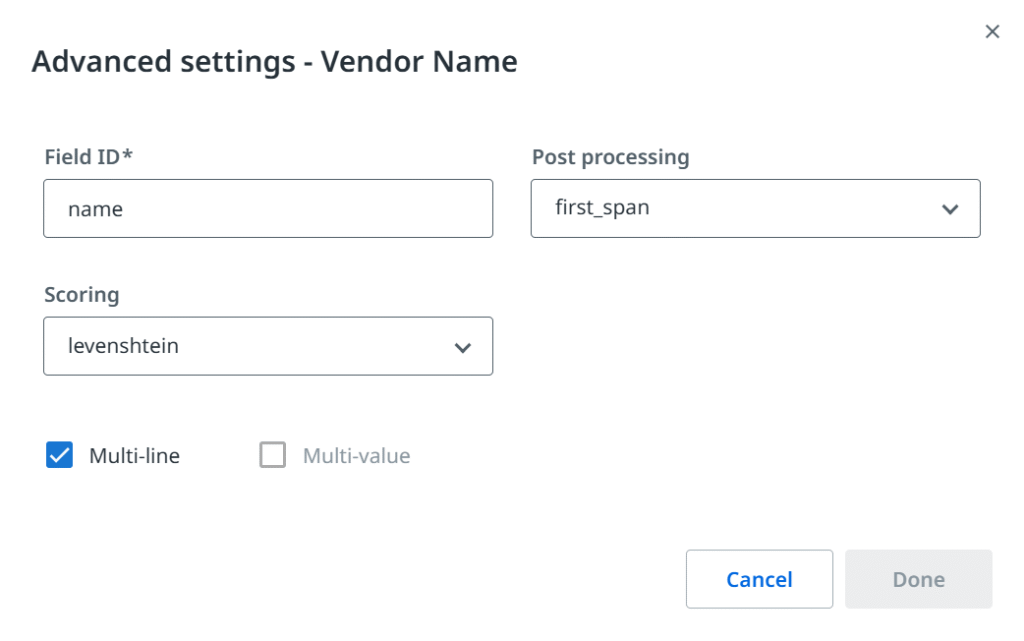
All those key elements: document types and fields determine our document processing project and are often referred to as taxonomy. Before we put it to use, we need to tackle one more human vs computer problem: vision.
Let it see what you see
Computers are perfectly fine with text – as long as it’s actually there. A PDF generated from Word or Excel usually contains real, selectable text. But not every document is like that (often called “native”). In many business cases, we still deal with scanned documents that are basically just images.
That’s where the IDP framework should include file digitization. This process usually means converting physical paper into an electronic format. Our incoming files are already digital, so in this context we refer to extraction of text from scanned documents or images, using the previously mentioned optical character recognition technologies.
For simplicity, let’s treat file digitization as covering both of these aspects. The good news is, printing and scanning is becoming less common and today’s OCR engines are significantly more efficient than they were a few years ago.
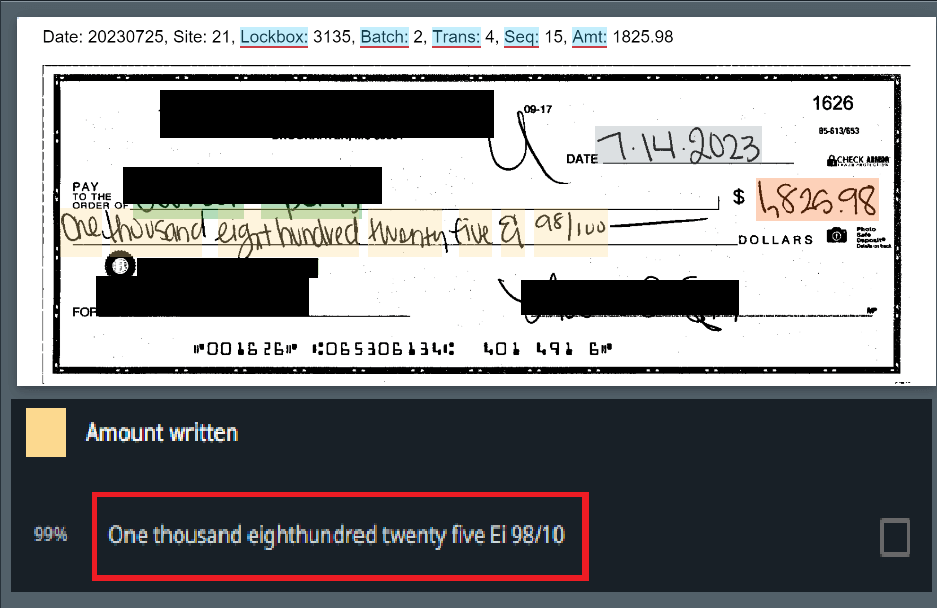
Nevertheless, be mindful about input data you intend to process. Scanned documents of bad quality or full of handwritten notes may pose a serious challenge even to the most powerful OCRs and potentially shoot down your automation project before it starts.
Putting things into boxes
Keeping order has always been relevant regardless if paper is physical or digital. Sorting various incoming types of documents may sound trivial, but it can greatly streamline our processes, especially high-volume ones.
In the area of intelligent document processing, categorizing into groups is called classification. The goal is simple: make the computer recognize what document type it is, but means to achieve it are an interesting topic.
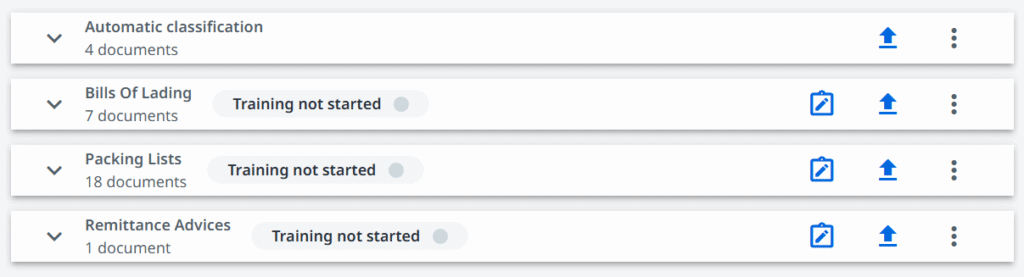
There are several methods varying in complexity. First thoughts usually lead us to keyword-based approaches. We look for specific and repetitive phrases, for example we expect the word “invoice” to appear at least once or even multiple times on a document. This technique is not limited to hardcoding words, we could also look for patterns, like consistent alphanumeric patterns, where regular expressions come in handy. Not explaining these, as they could easily fill a separate article.
Real cases are usually more tricky. Keywords appear irregularly or overlap between document types, some words are more significant than others. To address these issues, the UiPath Document Understanding™ framework offers advanced classifiers enhanced with artificial intelligence.
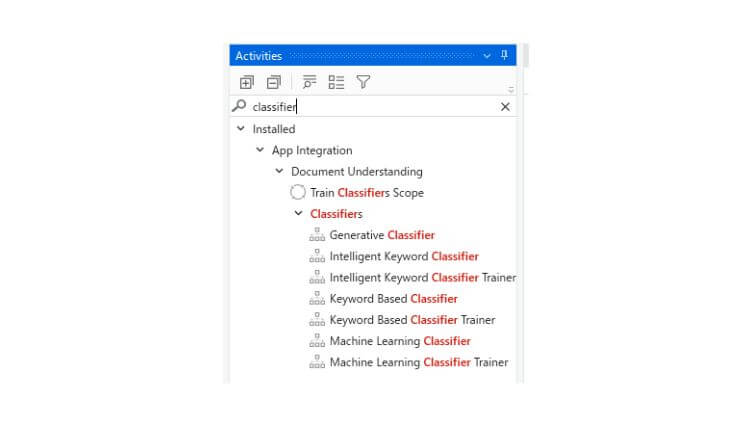
We have an option to build our own dedicated machine learning classifier that is trained on our documents. The actual features and architecture used when building the model are unknown (intellectual property), but in a nutshell the algorithm learns distinctive patterns from examples we provide. Document Understanding™ simplifies the training, which we’ll cover later in the article.
Another option is the intelligent keyword classifier, where the engine chooses the words on its own and assigns weights to each. It’s a simple to configure, yet well rounded option, which additionally can split multiple documents merged into a single file.
At last, as you could expect from the current genAI boom, there’s also an option to make a Large Language Model do the heavy lifting. We get to choose from a variety of LLMs and the configuration boils down to writing effective classification prompts.
Extracting information
Taxonomy defines which fields we want and now it’s finally time to extract data. Extractors of the UiPath Document Understanding™ framework follow a similar pattern to what we’ve covered with classifiers: from simple keyword-based data extraction all the way to powerful machine learning and genAI options. Configuring extraction is almost seamless, the components extract information which we specified in the taxonomy and return values assigned to created variables. Simple.

What could be a bit more challenging is to correctly foresee and assign data types along with additional options, like allowing a field to be multi-line (e.g. addresses) or multi-value (e.g. e-mail addresses). We can set each field as a string type, but the model may work better if we allow it to look for “monetary quantity” and automatically convert the value.
Field definitions also play a key role: order date and delivery date are both represented by date format, but they represent two different pieces of information. Extra time spent on carefully building your taxonomy should reward you with an efficient and precise data extraction.
From prediction to validation
By now we know about classification and extraction and that intelligent document processing is neither magic nor guesswork.
Nevertheless, even most advanced and sufficiently trained models make mistakes. Any AI-flavoured automation will never be 100% correct, when the test sample is large enough to take luck out of the equation. Error rate can still be lower compared to manual processing (especially with large volumes), but the target numbers will depend on a given business case.
Moving on, the key point is how to handle model mistakes. UiPath Document Understanding™ framework introduces a concept of confidence level indicated by a percentage value. It is often confused with probability, but it represents the model’s certainty that the returned classification or extraction result is the right answer, considering the whole context like OCR efficiency, location, field definition, etc.
With a 0-100% value for each classification and extraction result (every field separately) at our disposal, it’s easy to imagine a scenario, where we set up acceptable thresholds, e.g.: we consider everything 90% and above as correct. Again, values will heavily depend on the business case, where error impact plays a significant role. Remember to ask yourself a question, what can happen if the model is 90% sure, but the data is actually wrong.
What to do if we end up below the threshold? One strategy would be to introduce human validation. Whenever AI is not confident enough – doesn’t mean it was wrong – we let a real person step in and check the output. Document Understanding™ provides ready-to-use integrated applications (Actions and Apps) where either can serve as a validation station. Basically, the functionality boils down to an easy-to-use interactive form, where the users see the document and results from automated document processing. Submitting the form sends validated data further down the stream.
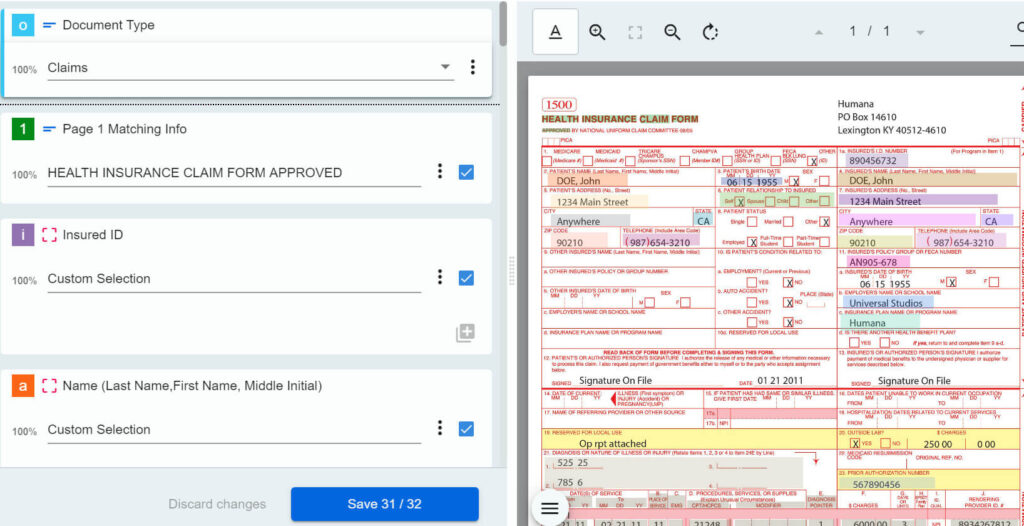
Confidence level is a super-useful feature, which lets us control the workflow depending on processing circumstances and risk factor. However, it’s even more powerful to combine it with rule-based validations: if any extracted data has an equivalent in our systems, we can compare the two values and control the flow based on that outcome.
Train the silicone brain
Since we’ve put all that work into reviewing classification and extracted data validation it would be a shame not to use it. Some frameworks, including UiPath Document Understanding™, offer us a method to capture the validated data and re-used it as training examples for further model training. This way our model can improve over time.
There’s also another stage where we want or even have to train a model. The out-of-the-box packages work quite well, but when we want to improve the efficiency for the pre-trained skill, we could immediately start a project with a labelling session. Same goes for custom document types – it’s like starting from a clean slate, so apart from defining a specific taxonomy we also have to train a custom model.
Fortunately, providing machine learning models with examples is super easy. Interface is very user friendly and boils down to confirming or selecting the right values on pages according to our taxonomy. It’s like a point-and-click coloring book.
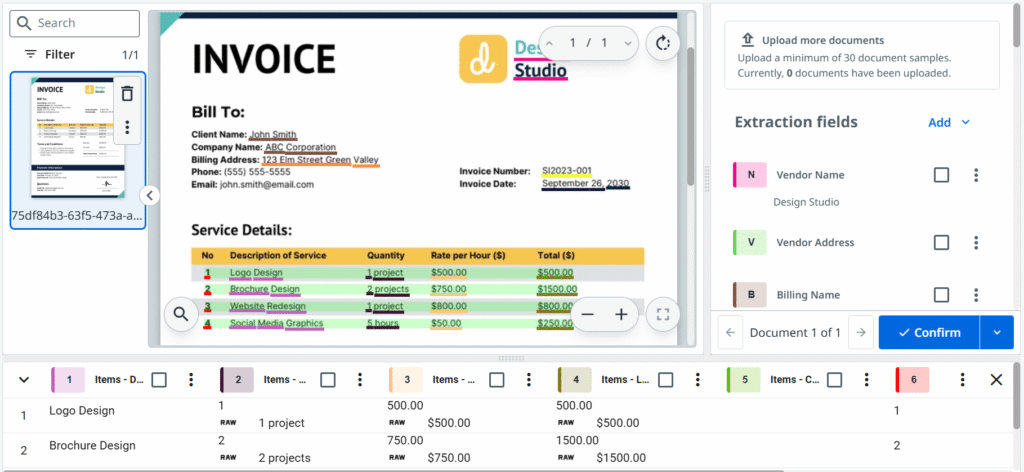
Going back to utilizing human feedback, a fully-automatic re-training loop can be achieved, but there are at least two caveats. Firstly, we are assuming that data output from the validation station is actually correct. Errors during extracted data validation are less likely, but still possible. Secondly, validation station requires only one value to be confirmed, whereas the training examples supplied to the model must point to all occurrences of a given field. In practice that means, only single page documents can be re-used unchanged as training examples.
Generally, it is a best practice to always review the sample before using it for training.
Main aim
We’ve reached the happy end – we are processing files with various document structures, classifying multiple document types and extracting data with validation and exception handling. It’s finally time to use the results in the target process – all in all we came all this way to actually do something with the vast amounts of documents we receive.
With the UiPath Document Understanding™ framework there isn’t much to do other than using ready-made activities that serve us the data on a silver platter. For those who’d like to use Document Understanding™ models but build the rest of the solution with another technology, there’s a friendly API at their disposal (more in UiPath documentation). Classification and extracting data cover most of the document processing scenarios one can find in a business operations in any organization: when you think of it, those two functions are all you need.
Processing invoices is only one example of a single workflow where the digital paper is just an unfortunate carrier of the information which needs to be transferred between two systems. Tools like UiPath Document Understanding™ are great at tackling the problem of automation that involves data trapped inside PDFs or scans.
If only we could find an alternative to sending each other such files.
Oh, wait…




