Papierlos zu arbeiten ist eine großartige Idee, aber es steckt mehr dahinter, als nur nichts auszudrucken. Der Punkt ist, dass Dokumente für Menschen zum Lesen gedacht sind, während Computer Daten verarbeiten. In den meisten Fällen der Dokumentenverarbeitung haben wir physisches Papier in ein binäres Äquivalent umgewandelt (meistens als PDFs – Portable Document Format – bekannt), was für Dinge, die Menschen lesen – Bücher, Zeitschriften, Broschüren und Ähnliches – völlig in Ordnung ist. Für automatisierte Workflows ist das jedoch schlecht.
Software-Roboter lesen nicht, sie laufen.
Wir werden sehen, wie sie mit UiPath Document Understanding laufen.
Der Schaden ist bereits angerichtet.
Wenn du im Büro arbeitest, hast du wahrscheinlich schon mit digitalen Dokumenten zu tun gehabt. Man muss keine Statistiken wälzen, um ihre Präsenz zu spüren, aber sehen wir uns an, was das Internet über die Nutzung von PDFs sagt.

Diese Zahlen sind ziemlich abstrakt. Dieselbe Website berichtet, dass die Erstellung von PDFs seit 2020 jährlich um etwa 12 % zunimmt. Sie sind überall, und dein Unternehmen erhält mit ziemlicher Sicherheit Rechnungen, Bestellungen oder Verträge in diesem Format.
Wir sollten uns über die Rettung von Bäumen, weniger Abfall und ein standardisiertes Format (ISO 32000) freuen, aber aus Sicht der Geschäftsautomatisierung war das ein Eigentor. Die Zahlen deuten darauf hin, dass PDFs nicht verschwinden werden, aber anstatt passiven Widerstand zu leisten, sprechen wir darüber, wie wir ihre Verarbeitung automatisieren können.
Was ist dein Problem?
Kurz gesagt, wir haben das Format für menschliche Augen entworfen und erwarten nun, dass Computer es verarbeiten. Für die ausführliche Version gehen wir ein typisches Beispiel durch: die Verarbeitung von Rechnungen als eingehende Dateien, z. B. als E-Mail-Anhänge.

Die menschliche Beteiligung ist klar definiert: Jemand im „Design Studio“ erstellt eine Rechnung – idealerweise mit einem ERP-System oder einer Anwendung – und sendet sie ab. Am anderen Ende empfängt jemand bei der „ABC Corporation“ die Datei und gibt die relevanten Daten manuell in das eigene ERP-System zur weiteren Verarbeitung ein. In der Regel ist es einfach, Schlüsselinformationen wie den Gesamtbetrag zu lesen.
Dennoch ist der Prozess repetitiv, fehleranfällig und zeitaufwendig. Es wäre viel einfacher, wenn beide Seiten sich darauf einigen würden, strukturierte Daten über eine geeignete Schnittstelle wie Electronic Data Interchange (EDI) auszutauschen. Leider ist das nach unserer Erfahrung eher die Ausnahme als die Regel.
Größere Initiativen wie nationale E-Invoicing-Systeme sind ein Schritt in die richtige Richtung, aber Rechnungen sind nur die Spitze des Eisbergs. Unternehmen verlassen sich täglich auf zahlreiche Dokumenttypen: Bestellungen, Lieferscheine, Frachtbriefe, CE-Zertifikate … die Liste ließe sich fortsetzen.
Die Suche nach der Wunderwaffe
Aus der Perspektive von Software-Robotern wird es schnell kompliziert. Ein Computer versteht nicht, was ein „Rechnungsdatum“ (Label) bedeutet, und es sind einige zusätzliche Schritte erforderlich, bevor wir diesen Wert tatsächlich nutzen können.
Hier betreten wir die Welt des Intelligent Document Processing (IDP) – einer Technologie, die künstliche Intelligenz (KI) einsetzt, um die Klassifizierung, Extraktion und Verarbeitung von Daten aus verschiedenen Dokumenttypen zu automatisieren. Sie kombiniert Technologien wie Machine Learning, Natural Language Processing (NLP) und Optical Character Recognition (OCR). Welches Framework oder welcher Lösungsanbieter genutzt wird, ist Geschmackssache; in diesem Artikel konzentrieren wir uns jedoch auf UiPath Document Understanding™ und zerlegen die Dokumentverarbeitungspipeline Schritt für Schritt.
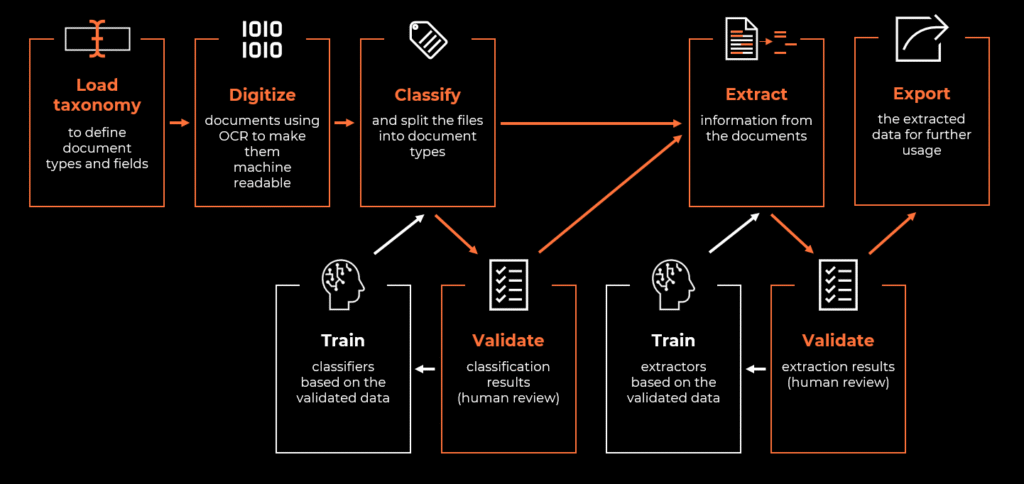
Sagen Sie mir also, was Sie wollen
Eine ordnungsgemäße Ausgangsanalyse ist für jede Automatisierung entscheidend, aber bei einem Projekt zur intelligenten Dokumentenverarbeitung ist sie absolut unerlässlich.
Beliebt aus gutem Grund
Zunächst müssen wir festlegen, welche Dokumenttypen in den Geltungsbereich fallen sollen. Technisch gesehen kann das jedes Dokument sein. Typische Rentabilitätskennzahlen wie das verarbeitete Volumen, der Zeitaufwand (FTE) oder menschliche Fehler helfen sicherlich dabei, die Auswahl einzugrenzen. Dies sind solide Grundlagen, aber bei der Automatisierung von Dokumenten-Workflows gibt es noch mehr zu beachten.
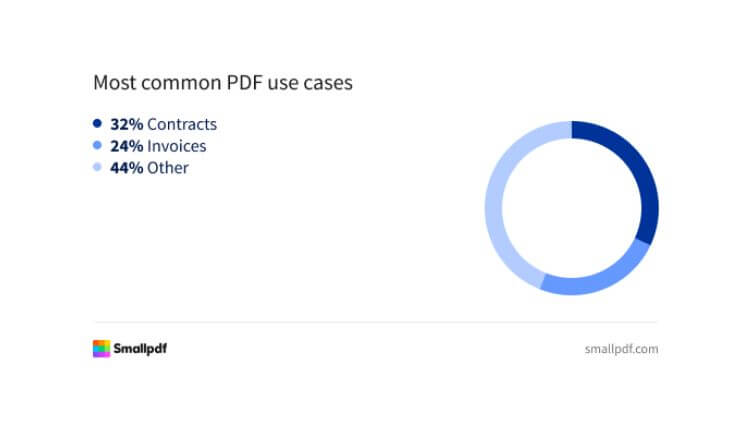
Die Häufigkeit von Dokumenten ist ein guter Indikator. Nicht nur, dass die Inhalte gut definiert sind (z.B. können Informationen, die auf Rechnungen erforderlich sind, durch lokale Gesetze geregelt sein), einige Anbieter bieten auch bereits trainierte Modelle für maschinelles Lernen für die meisten gängigen Dokumenttypen an. Genau das ist bei dem UiPath Document Understanding™ Framework und seinen Out-of-the-box-Paketen mit vortrainierten Modellen der Fall. Wenn es für Ihren Dokumententyp ein entsprechendes Paket gibt – verwenden Sie es. Es wird Ihr Projekt mit einer effizienten Basis für die Klassifizierung und Extraktion starten (mehr dazu später), ohne dass Sie Ihr eigenes maschinelles Lernmodell erstellen müssen.
Verschiedene Schattierungen der Rechnung
Selbst wenn wir nur einige wenige Dokumenttypen haben, könnten wir mit mehreren Layouts konfrontiert sein. In unserem Beispiel kann jedes Unternehmen, das uns eine Rechnung stellt, seine eigene Formatierung, sein eigenes Tabellenschema, seine eigene Kopfzeile, seine eigene Fußzeile (oder das Fehlen einer solchen) und so weiter haben. Dies bringt uns zu einer informellen Einteilung in 3 Gruppen: strukturierte, halbstrukturierte und unstrukturierte Dokumente.
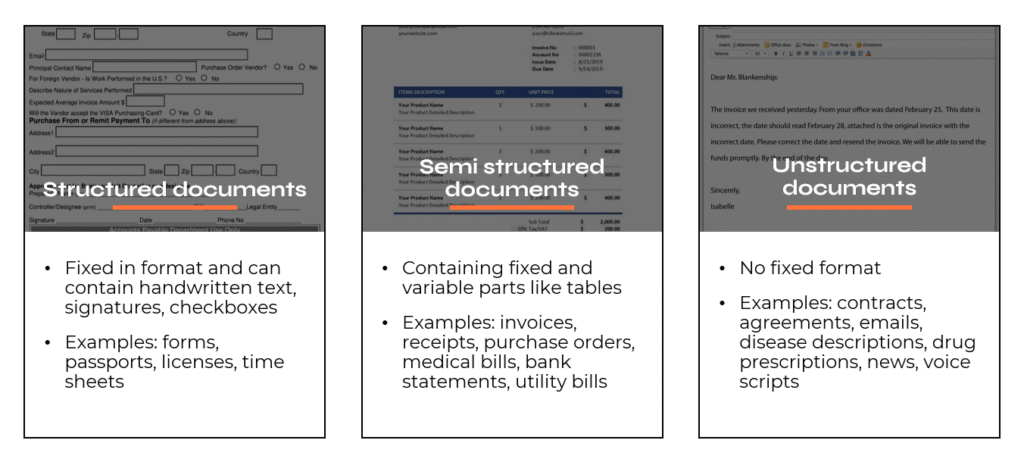
Die frühere Generation von Dokumentverarbeitungsprogrammen war stark von Layouts abhängig, die im Grunde als Schablone hart kodiert waren, z.B.: Suchen Sie ein Wort und bewegen Sie es um eine Position nach rechts, um einen Wert zu erhalten. Dieser Ansatz ist sehr anfällig für Änderungen und erfordert ständige Überwachung und Wartung.
Die gute Nachricht ist, dass moderne Frameworks wie UiPath Document Understanding™ layoutunabhängig sind. Wenn wir also ein bisher ungesehenes Dokument erhalten, sollte es mit ähnlicher Genauigkeit verarbeitet werden (ein paar Prozent Abweichung) und den Arbeitsablauf nicht unterbrechen. Dennoch sollten wir den Layouts große Aufmerksamkeit schenken und sie sorgfältig analysieren, bevor wir eine Automatisierung der Dokumentenverarbeitung entwickeln. Layouts können sehr kreativ sein, was das menschliche Auge erfreuen mag, aber für einen Computer eine harte Nuss sein kann.
Die wichtigsten Informationen
Unter Berücksichtigung des oben Beschriebenen ist es nun an der Zeit, Felder zu definieren. Das sind im Wesentlichen Informationen, die wir aus dem Dokument extrahieren möchten. Auch hier gilt, dass die gängigsten Felder oft in vorgefertigten Paketen zu finden sind, und es lohnt sich, diese Basiseffizienz zu nutzen, aber Ihr Geschäftsfall wird die Zielmenge bestimmen.
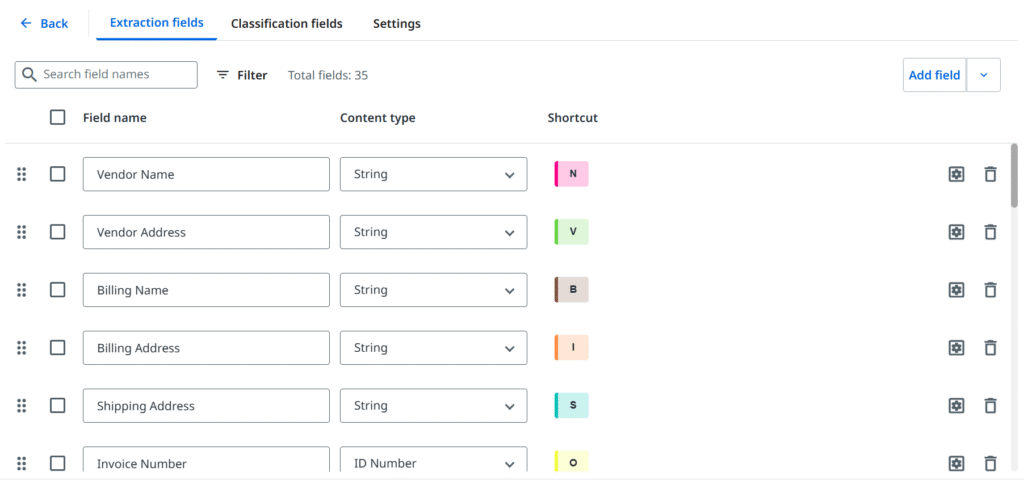
– Dokumenttyp-Manager
In den meisten Szenarien geben wir zwei Gruppen von extrahierten Daten an. Erstens allgemeine Felder (auf Kopfebene), die in der Regel einmal auf einer Seite vorkommen und (nicht immer) einwertig sind, z.B.: Rechnungsnummer, Datum oder Gesamtbetrag. Dann enthalten viele Dokumente eine Zeilen- und Spaltenstruktur, die sich perfekt für Tabellenfelder eignet, bei denen wir die Kopfzeile erstellen und eine unbestimmte Anzahl von Zeilen erstellen können, die sich sogar über mehrere Seiten erstrecken können. Die Arbeit mit Tabellen ist praktisch, aber (wieder) können Layouts durch sich überschneidende Zellwerte, durch andere Inhalte getrennte Zeilen oder (Achtung!) verschachtelte Tabellen übermäßig komplex werden – dies kann andere Ansätze oder fortgeschrittenere Techniken erfordern.
Einige Frameworks können auch zusätzliche Funktionen wie Nachbearbeitungsmethoden für Werte oder verschiedene Algorithmen für die Bewertung von Übereinstimmungen einführen. Es ist erwähnenswert, dass UiPath Document Understanding™ zusätzliche Klassifizierungsfelder einführt (nicht zu verwechseln mit dem Dokumententyp). Diese können nützlich sein, wenn wir eine weitere Unterteilung einführen und Dokumente auf der Grundlage von Währung, Sprache, Untertyp (z.B. Gutschrift) usw. kategorisieren möchten.
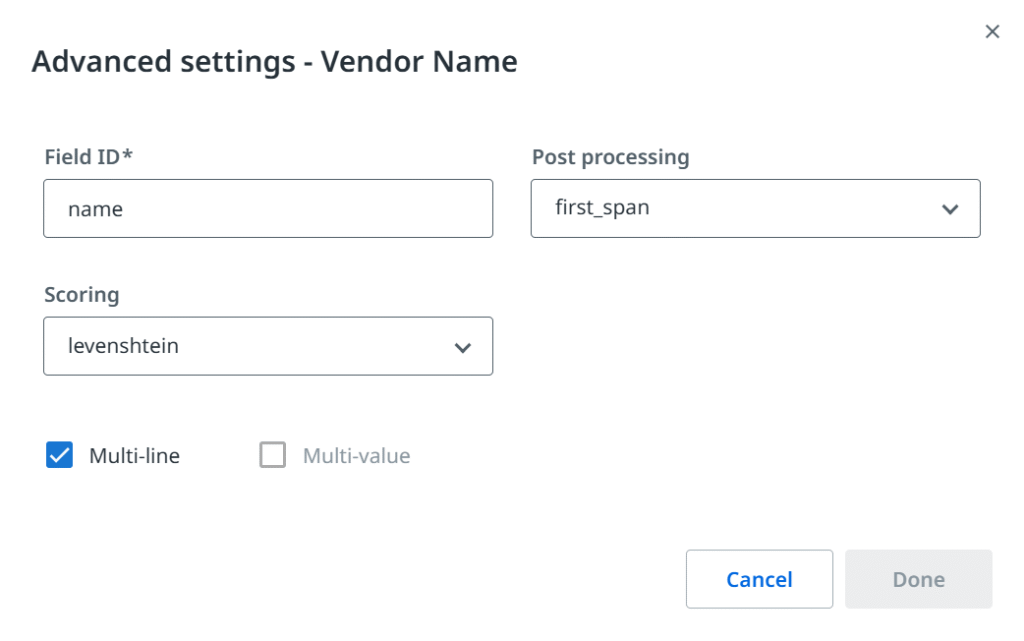
All diese Schlüsselelemente: Dokumenttypen und Felder bestimmen unser Projekt zur Dokumentenverarbeitung und werden oft als Taxonomie bezeichnet. Bevor wir sie anwenden können, müssen wir noch ein weiteres Problem zwischen Mensch und Computer angehen: das Sehen.
Lassen Sie es sehen, was Sie sehen
Computer kommen mit Text gut zurecht – solange er tatsächlich vorhanden ist. Ein aus Word oder Excel generiertes PDF enthält normalerweise echten, auswählbaren Text. Aber nicht jedes Dokument ist so (oft als „nativ“ bezeichnet). In vielen Geschäftsfällen haben wir es immer noch mit gescannten Dokumenten zu tun, die im Grunde nur Bilder sind.
An dieser Stelle sollte das IDP-Rahmenwerk die Digitalisierung von Akten beinhalten. Dieser Prozess bedeutet normalerweise die Umwandlung von physischem Papier in ein elektronisches Format. Unsere eingehenden Dateien sind bereits digital, daher beziehen wir uns in diesem Zusammenhang auf die Extraktion von Text aus gescannten Dokumenten oder Bildern unter Verwendung der bereits erwähnten Technologien zur optischen Zeichenerkennung.
Der Einfachheit halber wollen wir die Digitalisierung von Dateien als beide Aspekte betrachten. Die gute Nachricht ist, dass das Drucken und Scannen immer seltener wird und die heutigen OCR-Engines wesentlich effizienter sind als noch vor einigen Jahren.
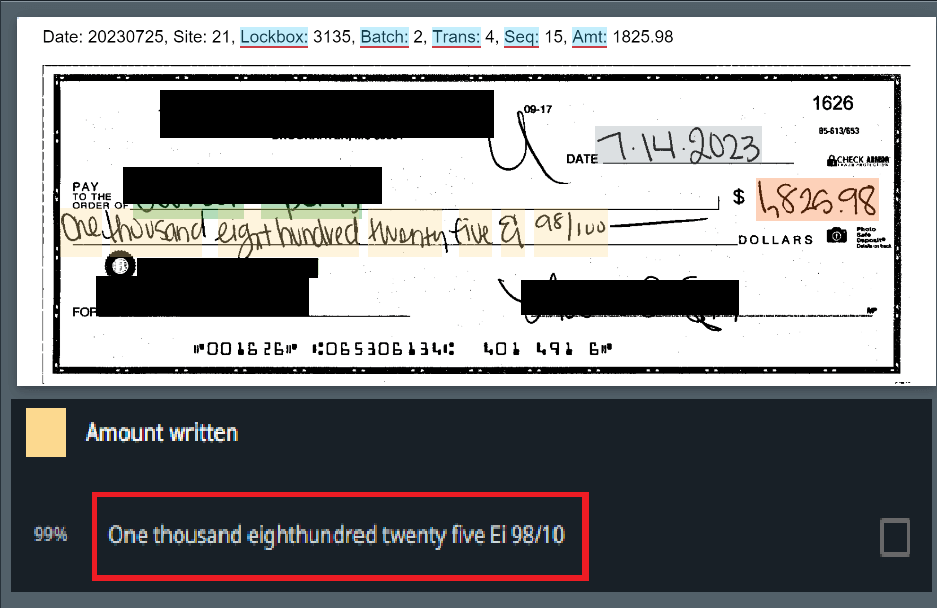
Achten Sie jedoch auf die Eingangsdaten, die Sie verarbeiten möchten. Gescannte Dokumente von schlechter Qualität oder mit handschriftlichen Notizen können selbst für die leistungsstärksten OCRs eine ernsthafte Herausforderung darstellen und Ihr Automatisierungsprojekt möglicherweise zum Scheitern bringen, bevor es überhaupt begonnen hat.
Dinge in Kisten packen
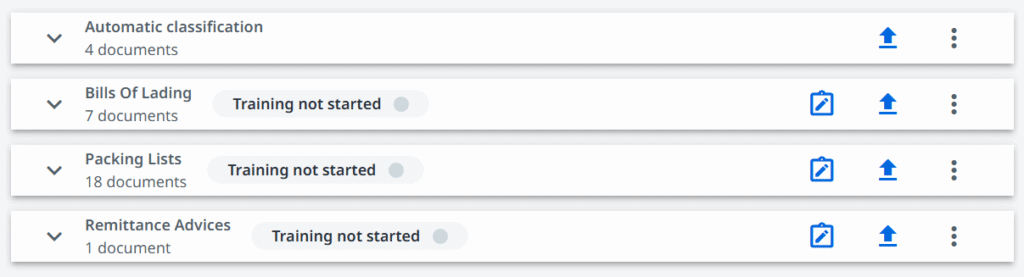
Ordnung zu halten war schon immer wichtig, egal ob es sich um physisches oder digitales Papier handelt. Die Sortierung der verschiedenen eingehenden Dokumenttypen mag trivial klingen, kann aber unsere Prozesse erheblich rationalisieren, insbesondere bei hohem Volumen.
Im Bereich der intelligenten Dokumentenverarbeitung wird die Einteilung in Gruppen als Klassifizierung bezeichnet. Das Ziel ist einfach: der Computer soll erkennen, um welche Art von Dokument es sich handelt, aber die Mittel, um dies zu erreichen, sind ein interessantes Thema.
Es gibt verschiedene Methoden, die unterschiedlich komplex sind. Der erste Gedanke führt uns normalerweise zu stichwortbasierten Ansätzen. Wir suchen nach bestimmten und sich wiederholenden Phrasen, z.B. erwarten wir, dass das Wort „Rechnung“ mindestens einmal oder sogar mehrmals in einem Dokument vorkommt. Diese Technik beschränkt sich nicht nur auf das Festschreiben von Wörtern, wir können auch nach Mustern suchen, z.B. nach konsistenten alphanumerischen Mustern, wobei reguläre Ausdrücke sehr nützlich sind. Ich erkläre diese nicht, da sie leicht einen eigenen Artikel füllen könnten.
Reale Fälle sind in der Regel komplizierter. Schlüsselwörter tauchen unregelmäßig auf oder überschneiden sich zwischen verschiedenen Dokumenttypen, einige Wörter sind bedeutender als andere. Um diese Probleme zu lösen, bietet das UiPath Document Understanding™ Framework fortschrittliche Klassifikatoren, die mit künstlicher Intelligenz erweitert wurden.
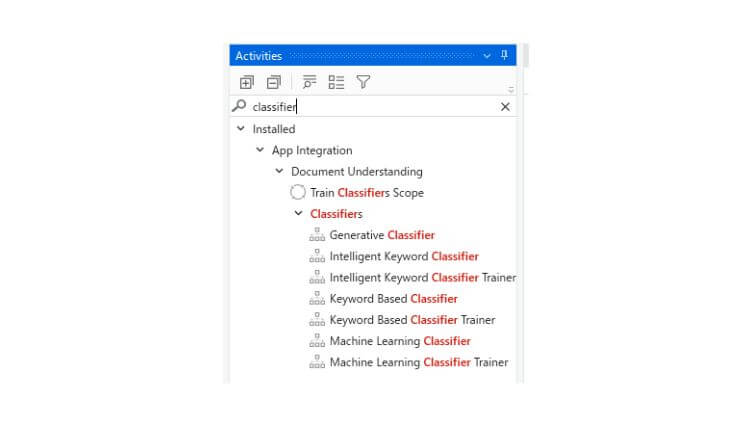
Wir haben die Möglichkeit, einen eigenen Klassifizierer für maschinelles Lernen zu erstellen, der auf unseren Dokumenten trainiert wird. Die tatsächlichen Merkmale und die Architektur, die bei der Erstellung des Modells verwendet werden, sind nicht bekannt (geistiges Eigentum), aber kurz gesagt, der Algorithmus lernt bestimmte Muster aus den von uns bereitgestellten Beispielen. Document Understanding™ vereinfacht das Training, auf das wir später in diesem Artikel eingehen werden.
Eine weitere Option ist der intelligente Schlüsselwortklassifikator, bei dem die Engine die Wörter selbst auswählt und ihnen eine Gewichtung zuweist. Es handelt sich um eine einfach zu konfigurierende, aber gut abgerundete Option, die zudem mehrere in einer einzigen Datei zusammengefasste Dokumente aufteilen kann.
Und schließlich gibt es, wie beim derzeitigen genAI-Boom nicht anders zu erwarten, auch eine Option, um ein Large Language Model die schwere Arbeit machen zu lassen. Wir können aus einer Vielzahl von LLMs wählen und die Konfiguration läuft darauf hinaus, effektive Klassifizierungsaufforderungen zu schreiben.
Informationen extrahieren
Die Taxonomie legt fest, welche Felder wir wollen, und nun ist es endlich an der Zeit, Daten zu extrahieren. Die Extraktoren des UiPath Document Understanding™ Frameworks folgen einem ähnlichen Muster wie die Klassifikatoren: von der einfachen schlagwortbasierten Datenextraktion bis hin zu leistungsstarken Optionen für maschinelles Lernen und genAI. Die Konfiguration der Extraktion erfolgt fast nahtlos. Die Komponenten extrahieren die Informationen, die wir in der Taxonomie angegeben haben, und geben Werte zurück, die den erstellten Variablen zugeordnet sind. Einfach.

Was etwas schwieriger sein könnte, ist die korrekte Vorhersage und Zuweisung von Datentypen zusammen mit zusätzlichen Optionen, z.B. dass ein Feld mehrzeilig (z.B. Adressen) oder mehrwertig (z.B. E-Mail-Adressen) sein kann. Wir können jedes Feld als String-Typ festlegen, aber das Modell funktioniert vielleicht besser, wenn wir es nach „Geldmenge“ suchen lassen und den Wert automatisch konvertieren.
Auch Felddefinitionen spielen eine wichtige Rolle: Bestelldatum und Lieferdatum werden beide durch das Datumsformat dargestellt, aber sie repräsentieren zwei unterschiedliche Informationen. Die zusätzliche Zeit, die Sie in den sorgfältigen Aufbau Ihrer Taxonomie investieren, sollte sich durch eine effiziente und präzise Datenextraktion auszahlen.
Von der Vorhersage zur Validierung
Inzwischen wissen wir über Klassifizierung und Extraktion Bescheid und dass intelligente Dokumentenverarbeitung weder Magie noch Rätselraten ist.
Dennoch machen auch die fortschrittlichsten und am besten trainierten Modelle Fehler. Jede KI-gestützte Automatisierung wird niemals zu 100 % korrekt sein, wenn die Teststichprobe groß genug ist, um das Glück aus der Gleichung zu nehmen. Die Fehlerquote kann im Vergleich zur manuellen Verarbeitung immer noch niedriger sein (insbesondere bei großen Mengen), aber die Zielzahlen hängen vom jeweiligen Geschäftsfall ab.
Der springende Punkt ist, wie man mit Modellfehlern umgeht. Das UiPath Document Understanding™ Framework führt ein Konzept des Konfidenzniveaus ein, das durch einen Prozentwert angegeben wird. Er wird oft mit der Wahrscheinlichkeit verwechselt, stellt aber die Gewissheit des Modells dar, dass das zurückgegebene Klassifizierungs- oder Extraktionsergebnis die richtige Antwort ist, unter Berücksichtigung des gesamten Kontexts wie OCR-Effizienz, Standort, Felddefinition usw.
Da wir für jedes Klassifizierungs- und Extraktionsergebnis (jedes Feld einzeln) einen Wert von 0-100% zur Verfügung haben, können wir uns leicht ein Szenario vorstellen, in dem wir akzeptable Schwellenwerte festlegen, z.B.: wir betrachten alles, was 90% und mehr beträgt, als korrekt. Auch hier hängen die Werte stark vom jeweiligen Geschäftsfall ab, in dem die Auswirkungen von Fehlern eine wichtige Rolle spielen. Denken Sie daran, sich die Frage zu stellen, was passieren kann, wenn das Modell zu 90% sicher ist, aber die Daten tatsächlich falsch sind.
Was ist zu tun, wenn wir den Schwellenwert unterschreiten? Eine Strategie wäre die Einführung einer menschlichen Validierung. Wann immer die KI nicht sicher genug ist – was nicht bedeutet, dass sie falsch lag – lassen wir einen echten Menschen einspringen und die Ausgabe überprüfen. Document Understanding™ bietet gebrauchsfertige integrierte Anwendungen (Actions und Apps), bei denen beide als Validierungsstation dienen können. Im Grunde läuft die Funktionalität auf ein einfach zu bedienendes interaktives Formular hinaus, in dem die Benutzer das Dokument und die Ergebnisse der automatischen Dokumentenverarbeitung sehen. Durch das Absenden des Formulars werden die validierten Daten weiterverarbeitet.
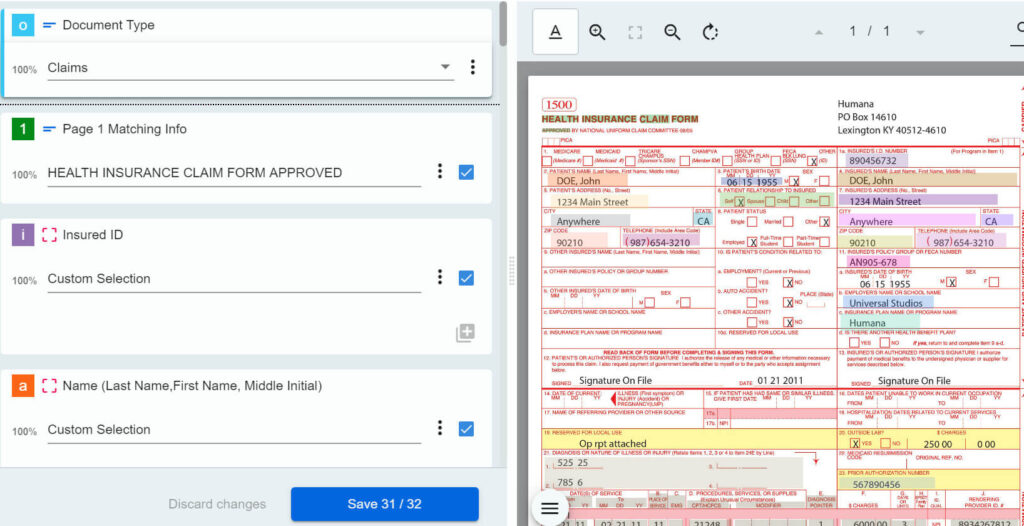
Die Vertrauensebene ist eine äußerst nützliche Funktion, mit der wir den Arbeitsablauf je nach Verarbeitungsbedingungen und Risikofaktor steuern können. Noch leistungsfähiger ist es jedoch, sie mit regelbasierten Validierungen zu kombinieren: Wenn extrahierte Daten eine Entsprechung in unseren Systemen haben, können wir die beiden Werte vergleichen und den Ablauf auf der Grundlage dieses Ergebnisses steuern.
Trainieren Sie das Silikongehirn
Da wir all diese Arbeit in die Überprüfung der Klassifizierung und die Validierung der extrahierten Daten gesteckt haben, wäre es schade, sie nicht zu nutzen. Einige Frameworks, darunter UiPath Document Understanding™, bieten uns eine Methode, um die validierten Daten zu erfassen und als Trainingsbeispiele für weiteres Modelltraining wiederzuverwenden. Auf diese Weise kann unser Modell im Laufe der Zeit verbessert werden.
Es gibt auch eine andere Phase, in der wir ein Modell trainieren wollen oder sogar müssen. Die vorgefertigten Pakete funktionieren recht gut, aber wenn wir die Effizienz der trainierten Fähigkeit verbessern wollen, können wir ein Projekt sofort mit einer Etikettierungssitzung beginnen. Dasselbe gilt für benutzerdefinierte Dokumenttypen – es ist, als würden wir bei Null anfangen, also müssen wir nicht nur eine spezifische Taxonomie definieren, sondern auch ein benutzerdefiniertes Modell trainieren.
Glücklicherweise ist die Bereitstellung von Machine Learning-Modellen mit Beispielen super einfach. Die Oberfläche ist sehr benutzerfreundlich und läuft darauf hinaus, die richtigen Werte auf den Seiten gemäß unserer Taxonomie zu bestätigen oder auszuwählen. Es ist wie ein Malbuch zum Zeigen und Anklicken.
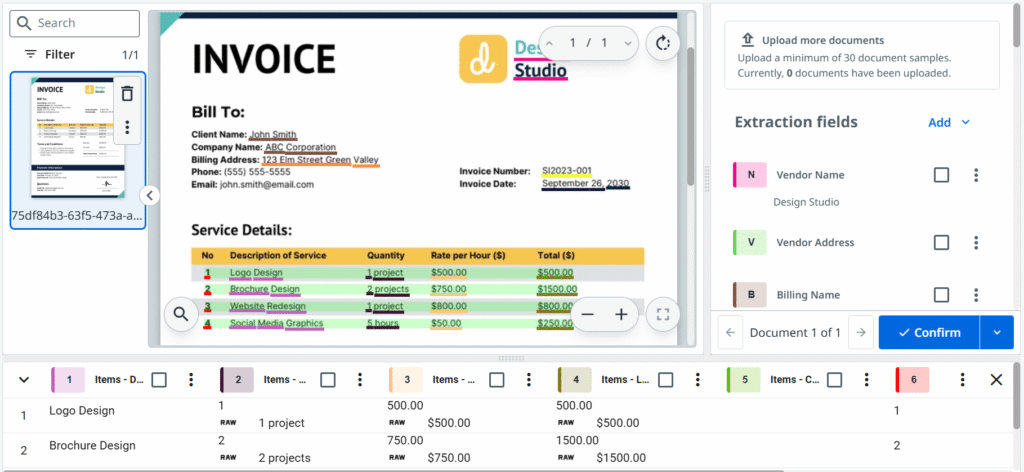
Um auf das menschliche Feedback zurückzukommen, kann eine vollautomatische Umschulungsschleife erreicht werden, aber es gibt mindestens zwei Vorbehalte. Erstens gehen wir davon aus, dass die von der Validierungsstation ausgegebenen Daten tatsächlich korrekt sind. Fehler bei der Validierung der extrahierten Daten sind zwar weniger wahrscheinlich, aber dennoch möglich. Zweitens muss bei der Validierungsstation nur ein Wert bestätigt werden, während die dem Modell gelieferten Trainingsbeispiele auf alle Vorkommen eines bestimmten Feldes hinweisen müssen. In der Praxis bedeutet das, dass nur einseitige Dokumente unverändert als Trainingsbeispiele wiederverwendet werden können.
Im Allgemeinen empfiehlt es sich, das Muster immer zu überprüfen, bevor Sie es zum Training verwenden.
Hauptziel
Wir haben das Happy End erreicht – wir verarbeiten Dateien mit verschiedenen Dokumentstrukturen, klassifizieren mehrere Dokumenttypen und extrahieren Daten mit Validierung und Ausnahmebehandlung. Jetzt ist es endlich an der Zeit, die Ergebnisse im Zielprozess zu verwenden – alles in allem sind wir den ganzen Weg gekommen, um tatsächlich etwas mit den riesigen Mengen an Dokumenten zu tun, die wir erhalten.
Mit dem UiPath Document Understanding™ Framework gibt es nicht viel zu tun, außer vorgefertigte Aktivitäten zu verwenden, die uns die Daten auf dem Silbertablett servieren. Für diejenigen, die Document Understanding™-Modelle verwenden, aber den Rest der Lösung mit einer anderen Technologie aufbauen möchten, steht eine freundliche API zur Verfügung (mehr in der UiPath-Dokumentation). Die Klassifizierung und die Extraktion von Daten decken die meisten Szenarien der Dokumentenverarbeitung ab, die in jedem Unternehmen vorkommen können: Wenn Sie darüber nachdenken, sind diese beiden Funktionen alles, was Sie brauchen.
Die Bearbeitung von Rechnungen ist nur ein Beispiel für einen einzelnen Workflow, bei dem das digitale Papier nur ein unglücklicher Träger der Informationen ist, die zwischen zwei Systemen übertragen werden müssen. Tools wie UiPath Document Understanding™ eignen sich hervorragend zur Lösung des Problems der Automatisierung, bei der Daten in PDFs oder Scans gefangen sind.
Wenn wir nur eine Alternative finden könnten, um uns solche Dateien gegenseitig zu schicken.
Oh, warten Sie…




