Przejście na pracę bez papieru to świetny pomysł, ale to coś więcej niż tylko rezygnacja z drukowania. Chodzi o to, że dokumenty są przeznaczone do czytania przez ludzi, podczas gdy komputery przetwarzają dane. W większości scenariuszy przetwarzania dokumentów zamieniliśmy fizyczny papier na jego binarny odpowiednik (najczęściej w postaci plików PDF – Portable Document Format), co jest w porządku w przypadku rzeczy czytanych przez ludzi: książek, magazynów, broszur i tym podobnych. Jednakże to złe rozwiązanie dla zautomatyzowanych przepływów pracy.
Roboty programowe nie czytają, one działają.
Zobaczymy, jak działają z UiPath Document Understanding.
Szkody już zostały wyrządzone
Jeśli pracujesz w biurze, jest duża szansa, że miałeś już do czynienia z dokumentami cyfrowymi. Nie trzeba zagłębiać się w statystyki, aby odczuć ich obecność, ale zobaczmy, co internet mówi o korzystaniu z PDF-ów.

Te liczby są dość abstrakcyjne. Ta sama strona podaje, że tworzenie plików PDF rośnie od 2020 roku o około 12% rocznie. Są wszędzie, a Twoja firma niemal na pewno otrzymuje faktury, zamówienia zakupu lub umowy w tym formacie.
Powinniśmy się cieszyć z oszczędzania drzew, mniejszej ilości odpadów czy ze standaryzowanego formatu (ISO 32000), ale z punktu widzenia automatyzacji biznesu był to trochę samobój. Liczby sugerują, że PDF-y nie znikną, ale zamiast biernego oporu porozmawiajmy o tym, jak zautomatyzować ich własne tworzenie.
Jaki jest twój problem?
W skrócie: zaprojektowaliśmy format dla ludzkich oczu, a teraz oczekujemy, że komputery będą go przetwarzać. W dłuższej wersji przejdźmy przez typowy przykład przetwarzania faktur jako plików przychodzących, np. jako załączników do e-maili.

Zaangażowanie człowieka jest dobrze zdefiniowane: ktoś w „Design Studio” tworzy fakturę, najlepiej przy użyciu systemu ERP lub jakiejś aplikacji, i wysyła ją dalej. Po drugiej stronie ktoś w „ABC Corporation” odbiera plik i ręcznie wprowadza odpowiednie dane do własnego systemu ERP w celu dalszego przetwarzania. Zazwyczaj łatwo jest odczytać kluczowe informacje, takie jak kwota całkowita.
Niemniej jednak proces ten jest powtarzalny, podatny na błędy i czasochłonny. Byłoby o wiele prościej, gdyby obie strony zgodziły się wymieniać ustrukturyzowane dane poprzez właściwy interfejs, taki jak Electronic Data Interchange (EDI). Niestety, z naszego doświadczenia wynika, że to wciąż bardziej wyjątek niż reguła.
Większe inicjatywy, takie jak krajowe systemy e-fakturowania, są krokiem we właściwym kierunku, ale faktury to tylko wierzchołek góry lodowej. Firmy polegają na wielu typach dokumentów każdego dnia: zamówieniach zakupu, listach przewozowych, konosamentach, certyfikatach CE… lista jest długa.
Znalezienie srebrnej kuli
Z perspektywy robotów programowych sprawy szybko stają się skomplikowane. Komputer nie rozumie, co oznacza „invoice date” (etykieta), i zanim będziemy mogli faktycznie wykorzystać tę wartość, konieczne są dodatkowe kroki.
W tym miejscu wkraczamy w świat Intelligent Document Processing (IDP) – technologii, która wykorzystuje sztuczną inteligencję (AI) do automatyzacji klasyfikacji, ekstrakcji i przetwarzania danych z różnych typów dokumentów. Łączy ona technologie takie jak uczenie maszynowe, przetwarzanie języka naturalnego (NLP) oraz optyczne rozpoznawanie znaków (OCR). Konkretny framework lub dostawca rozwiązania jest kwestią preferencji, ale na potrzeby tego artykułu przyjrzymy się bliżej UiPath Document Understanding™ i rozłożymy proces przetwarzania dokumentów krok po kroku.
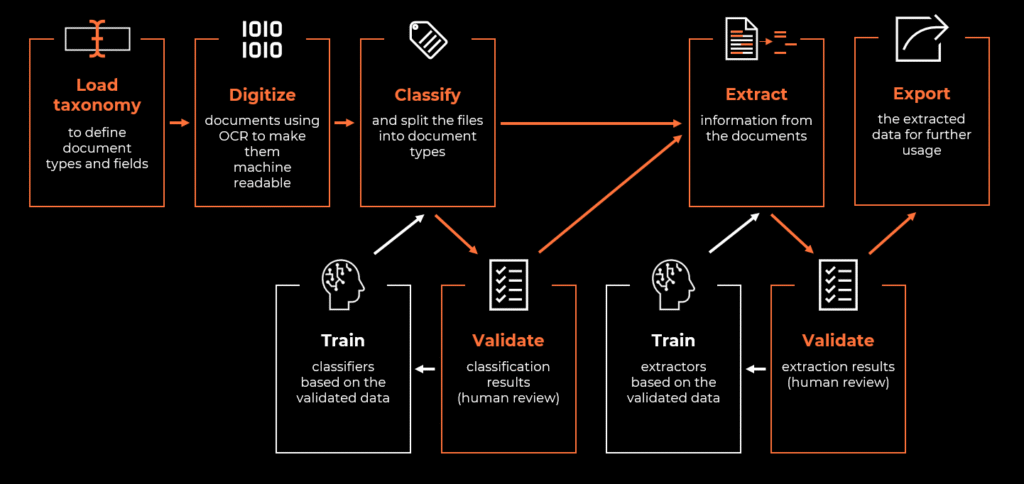
A więc powiedz mi, czego chcesz.
Odpowiednia analiza wstępna ma kluczowe znaczenie dla każdej automatyzacji, ale w projekcie inteligentnego przetwarzania dokumentów jest absolutnie niezbędna.
Popularne z jakiegoś powodu
Najpierw musimy zdefiniować, jakie typy dokumentów powinny znaleźć się w zakresie. Technicznie rzecz biorąc, mogą to być dowolne typy, więc typowe wskaźniki rentowności, takie jak wolumen przetwarzanych dokumentów, poświęcony czas (FTE) czy liczba błędów ludzkich, z pewnością pomogą zawęzić wybór. To solidne podstawy, ale przy automatyzacji przepływów dokumentów trzeba wziąć pod uwagę coś więcej.
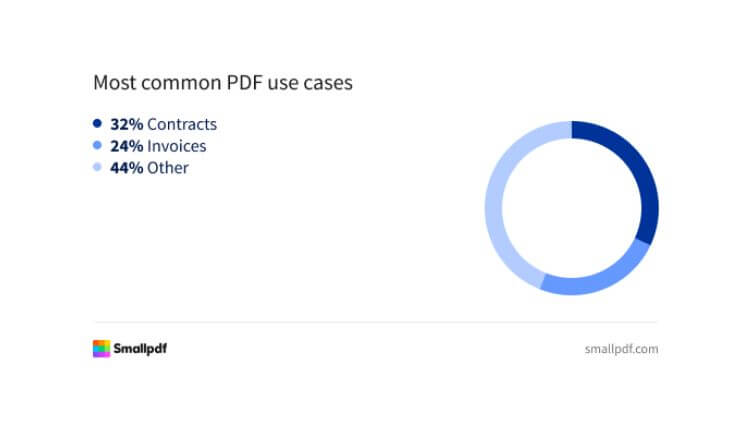
Powszechność dokumentów jest dobrym wskaźnikiem. Nie tylko treść jest dobrze zdefiniowana (np. informacje wymagane na fakturach mogą być regulowane przez lokalne prawo), ale niektórzy dostawcy oferują wstępnie wytrenowane modele uczenia maszynowego dla najpopularniejszych typów dokumentów. Tak właśnie jest w przypadku frameworka UiPath Document Understanding™ i jego gotowych, wstępnie wytrenowanych pakietów. Jeśli Twój typ dokumentu ma odpowiedni pakiet – użyj go – dzięki temu Twój projekt wystartuje z podstawową efektywnością w zakresie klasyfikacji i ekstrakcji (więcej na ten temat później) bez konieczności budowania własnego modelu uczenia maszynowego.
Różne odcienie faktury
Nawet jeśli mamy tylko kilka typów dokumentów, możemy spotkać się z wieloma różnymi układami. W naszym przykładzie każda organizacja wystawiająca nam fakturę może mieć własne formatowanie, schemat tabeli, umiejscowienie nagłówka, stopki (lub jej brak) i tak dalej. To prowadzi nas do nieformalnego podziału na 3 grupy: dokumenty ustrukturyzowane, częściowo ustrukturyzowane oraz nieustrukturyzowane.
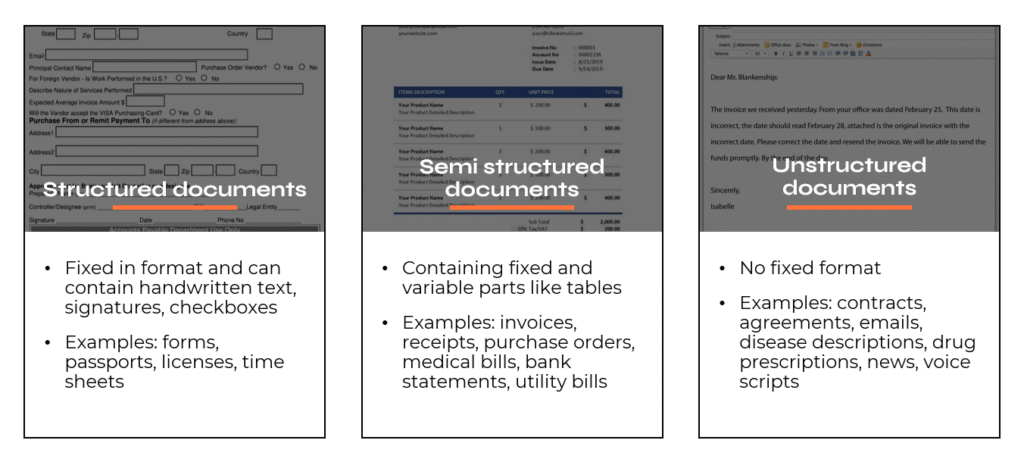
Poprzednia generacja narzędzi do przetwarzania dokumentów była silnie uzależniona od układów, z których każdy był w zasadzie zakodowany na sztywno jako szablon, np.: zlokalizuj słowo i przesuń się o jedną pozycję w prawo, aby uzyskać wartość. Takie podejście jest bardzo podatne na zmiany i wymaga ciągłego monitorowania oraz utrzymania.
Dobra wiadomość jest taka, że nowoczesne frameworki, takie jak UiPath Document Understanding™, są niezależne od układu, więc gdy otrzymamy wcześniej niewidziany dokument, powinien on zostać obsłużony z podobną dokładnością (z odchyleniem o kilka procent) i nie powinien powodować awarii procesu. Niemniej jednak powinniśmy zwracać szczególną uwagę na układy i dokładnie je analizować przed zbudowaniem automatyzacji przetwarzania dokumentów. Układy potrafią być bardzo kreatywne, co może cieszyć ludzkie oko, ale dla komputera może stanowić twardy orzech do zgryzienia.
Kluczowe informacje
Mając na uwadze to, co zostało opisane powyżej, wreszcie nadchodzi czas na zdefiniowanie pól, czyli zasadniczo fragmentów informacji, które chcemy wyodrębnić z dokumentu. Ponownie, te najczęściej występujące można często znaleźć w pakietach wstępnie wytrenowanych i warto korzystać z tej bazowej efektywności, lecz to Twój przypadek biznesowy określi docelowy zestaw.
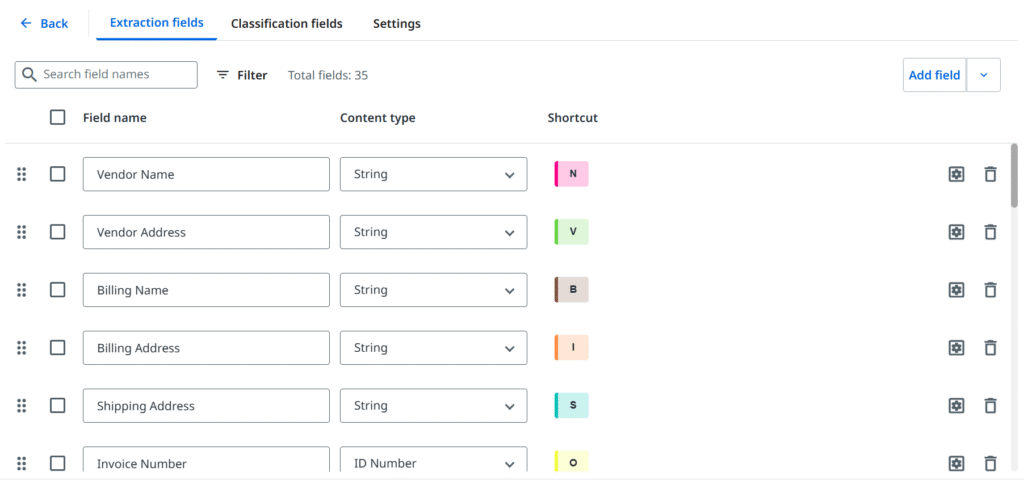
– Document type manager
W większości scenariuszy określamy dwie grupy danych do wyodrębnienia. Po pierwsze, ogólne pola (na poziomie nagłówka), które zazwyczaj pojawiają się jednokrotnie na jednej stronie i mają pojedynczą wartość (choć nie zawsze), na przykład: numer faktury, data czy kwota całkowita. Następnie wiele dokumentów zawiera strukturę wierszy i kolumn, co idealnie nadaje się do pól tabelarycznych, gdzie tworzymy nagłówek i możemy obsłużyć dowolną liczbę wierszy, nawet obejmujących wiele stron.
Tabele są wygodne w pracy, ale (znowu) układy mogą być nadmiernie złożone — z nakładającymi się wartościami komórek, wierszami przedzielonymi inną treścią lub (uwaga!) zagnieżdżonymi tabelami, które mogą wymagać innych podejść lub bardziej zaawansowanych technik.
Niektóre frameworki mogą również wprowadzać dodatkowe funkcje, takie jak metody post-przetwarzania wartości lub różne algorytmy oceny dopasowania. Warto wspomnieć, że UiPath Document Understanding™ udostępnia dodatkowe pola klasyfikacyjne (nie mylić z typem dokumentu). Mogą one być przydatne, gdy chcemy wprowadzić dalszy podział i kategoryzować dokumenty na podstawie waluty, języka, podtypu (np. nota kredytowa) itp.
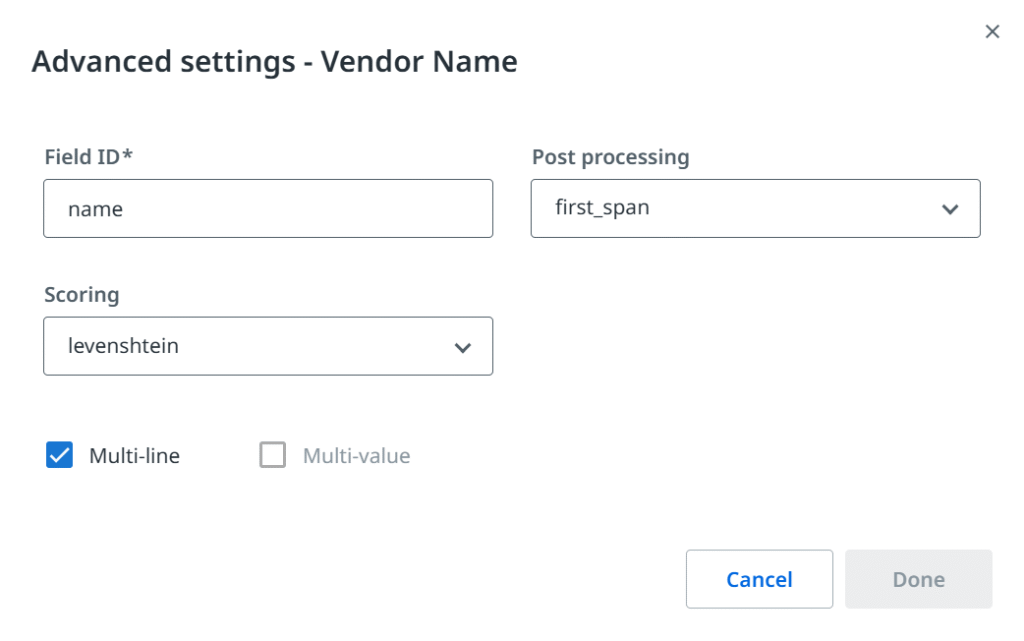
Wszystkie te kluczowe elementy — typy dokumentów i pola — określają nasz projekt przetwarzania dokumentów i często nazywane są taksonomią. Zanim jednak zaczniemy z niej korzystać, musimy zmierzyć się z jeszcze jednym problemem człowiek kontra komputer: widzeniem.
Pozwól mu zobaczyć to, co Ty widzisz
Komputery doskonale radzą sobie z tekstem — o ile ten tekst faktycznie tam jest. PDF wygenerowany z Worda lub Excela zazwyczaj zawiera prawdziwy, możliwy do zaznaczenia tekst. Jednak nie każdy dokument taki jest (często nazywa się je „natywnymi”). W wielu przypadkach biznesowych wciąż mamy do czynienia ze skanami dokumentów, które są w zasadzie tylko obrazami.
W tym miejscu framework IDP powinien obejmować digitalizację plików. Proces ten zazwyczaj oznacza konwersję fizycznego papieru do formatu elektronicznego. Nasze pliki przychodzące są już cyfrowe, więc w tym kontekście mówimy o ekstrakcji tekstu ze skanowanych dokumentów lub obrazów, z wykorzystaniem wspomnianych wcześniej technologii optycznego rozpoznawania znaków.
Dla uproszczenia potraktujmy digitalizację plików jako obejmującą oba te aspekty. Dobrą wiadomością jest to, że drukowanie i skanowanie staje się coraz rzadsze, a współczesne silniki OCR są znacznie bardziej wydajne niż kilka lat temu.
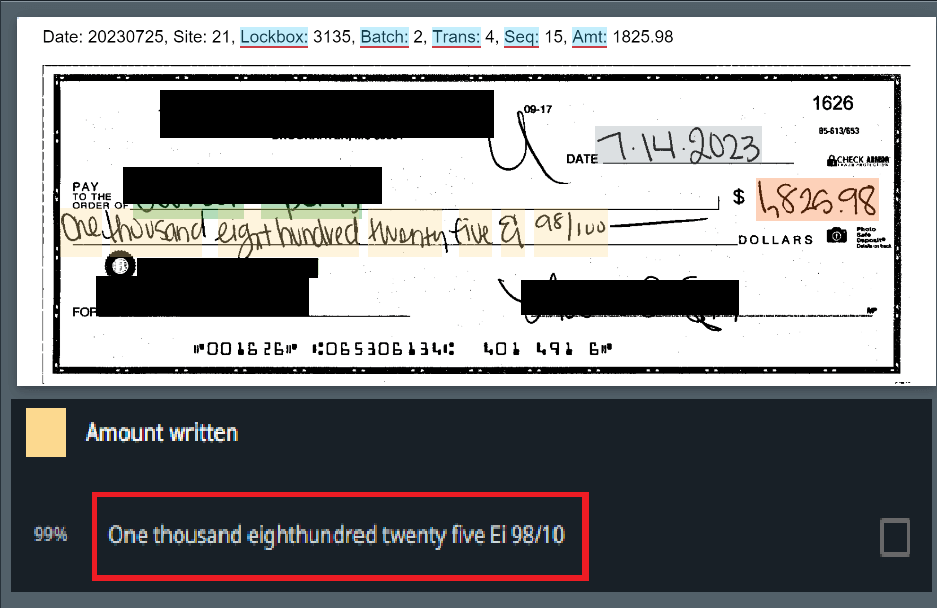
Niemniej jednak zwracaj uwagę na dane wejściowe, które zamierzasz przetwarzać. Zeskanowane dokumenty złej jakości lub pełne odręcznych notatek mogą stanowić poważne wyzwanie nawet dla najpotężniejszych silników OCR i potencjalnie pogrzebać Twój projekt automatyzacji, zanim jeszcze wystartuje.
Układanie rzeczy w pudełkach
Utrzymanie porządku zawsze miało znaczenie, niezależnie od tego, czy papier jest fizyczny, czy cyfrowy. Sortowanie różnych typów nadchodzących dokumentów może brzmieć banalnie, ale może znacznie usprawnić nasze procesy, zwłaszcza te o dużej skali.
W obszarze inteligentnego przetwarzania dokumentów kategoryzowanie ich w grupy nazywa się klasyfikacją. Cel jest prosty: sprawić, aby komputer rozpoznał, jakiego typu jest dany dokument, ale sposoby osiągnięcia tego celu są ciekawym zagadnieniem.
Istnieje kilka metod o różnym poziomie złożoności. Pierwsze skojarzenia prowadzą zwykle do podejść opartych na słowach kluczowych. Szukamy konkretnych i powtarzalnych fraz — na przykład oczekujemy, że słowo „invoice” pojawi się na dokumencie co najmniej raz lub nawet wielokrotnie. Technika ta nie ogranicza się do twardego kodowania słów — możemy również szukać wzorców, takich jak spójne wzorce alfanumeryczne, gdzie przydatne stają się wyrażenia regularne. Nie będę ich tu wyjaśniać, ponieważ z łatwością mogłyby wypełnić osobny artykuł.
W rzeczywistych przypadkach bywa zwykle trudniej. Słowa kluczowe pojawiają się nieregularnie lub pokrywają się między typami dokumentów, a niektóre słowa mają większe znaczenie niż inne. Aby rozwiązać te problemy, framework UiPath Document Understanding™ oferuje zaawansowane klasyfikatory wspierane sztuczną inteligencją.
Mamy możliwość zbudowania własnego, dedykowanego klasyfikatora opartego na uczeniu maszynowym, trenowanego na naszych dokumentach. Rzeczywiste cechy i architektura używane przy budowaniu modelu są nieznane (własność intelektualna), ale w skrócie algorytm uczy się charakterystycznych wzorców z podawanych przez nas przykładów. Document Understanding™ upraszcza proces treningu, który omówimy później w artykule.
Inną opcją jest inteligentny klasyfikator słów kluczowych, w którym silnik samodzielnie wybiera słowa i przypisuje im wagi. To proste w konfiguracji, a jednocześnie wszechstronne rozwiązanie, które dodatkowo potrafi podzielić wiele dokumentów połączonych w jeden plik.
W końcu, jak można się spodziewać po obecnym boomie na genAI, istnieje również opcja, aby ciężką pracę wykonał duży model językowy. Możemy wybierać spośród różnych LLM-ów, a konfiguracja sprowadza się do napisania skutecznych promptów klasyfikacyjnych.
Wyodrębnianie informacji
Taksonomia definiuje, które pola chcemy uzyskać, i teraz wreszcie nadchodzi czas na wyodrębnienie danych. Ekstraktory frameworka UiPath Document Understanding™ podążają podobnym schematem jak klasyfikatory: od prostej ekstrakcji danych opartej na słowach kluczowych, aż po zaawansowane opcje oparte na uczeniu maszynowym i genAI. Konfiguracja ekstrakcji jest niemal bezproblemowa — komponenty wyodrębniają informacje, które określiliśmy w taksonomii, i zwracają wartości przypisane do utworzonych zmiennych. Proste.

To, co może być nieco bardziej wymagające, to poprawne przewidzenie i przypisanie typów danych wraz z dodatkowymi opcjami, takimi jak umożliwienie polu bycia wielowierszowym (np. adresy) lub wielowartościowym (np. adresy e-mail). Możemy ustawić każde pole jako typ string, ale model może działać lepiej, jeśli pozwolimy mu szukać „monetary quantity” i automatycznie konwertować wartość.
Definicje pól również odgrywają kluczową rolę: order date i delivery date są obydwa reprezentowane w formacie daty, ale oznaczają dwa różne fragmenty informacji. Dodatkowy czas poświęcony na staranne zbudowanie taksonomii powinien zaowocować wydajną i precyzyjną ekstrakcją danych.
Od predykcji do walidacji
Do tej pory wiemy już o klasyfikacji i ekstrakcji oraz o tym, że inteligentne przetwarzanie dokumentów nie jest ani magią, ani zgadywanką.
Niemniej jednak nawet najbardziej zaawansowane i odpowiednio wytrenowane modele popełniają błędy. Każda automatyzacja z elementami AI nigdy nie będzie w 100% poprawna, gdy próbka testowa jest wystarczająco duża, aby wykluczyć czynnik szczęścia. Wskaźnik błędów może być nadal niższy w porównaniu z przetwarzaniem ręcznym (szczególnie przy dużych wolumenach), ale docelowe wartości będą zależeć od konkretnego przypadku biznesowego.
Przechodząc dalej, kluczową kwestią jest to, jak obsługiwać błędy modelu. Framework UiPath Document Understanding™ wprowadza pojęcie poziomu pewności określanego wartością procentową. Często bywa on mylony z prawdopodobieństwem, lecz reprezentuje stopień przekonania modelu, że zwrócony wynik klasyfikacji lub ekstrakcji jest poprawny, biorąc pod uwagę cały kontekst, taki jak efektywność OCR, lokalizacja, definicja pola itp.
Dysponując wartością 0–100% dla każdego wyniku klasyfikacji i ekstrakcji (dla każdego pola osobno), łatwo wyobrazić sobie scenariusz, w którym ustawiamy akceptowalne progi, np.: uznajemy wszystko powyżej 90% za poprawne. Ponownie, wartości będą w dużym stopniu zależały od przypadku biznesowego, w którym wpływ błędu odgrywa istotną rolę. Pamiętaj, aby zadać sobie pytanie, co może się stać, jeśli model jest pewny wyniku w 90%, ale dane w rzeczywistości są błędne.
Co zrobić, jeśli wynik znajdzie się poniżej progu? Jedną ze strategii byłoby wprowadzenie walidacji przez człowieka. Kiedy AI nie jest wystarczająco pewne — co nie oznacza, że się myli — pozwalamy prawdziwej osobie wkroczyć i sprawdzić wynik. Document Understanding™ udostępnia gotowe, zintegrowane aplikacje (Actions i Apps), z których każda może pełnić rolę stacji walidacyjnej. W praktyce funkcjonalność sprowadza się do łatwego w obsłudze interaktywnego formularza, w którym użytkownicy widzą dokument oraz wyniki automatycznego przetwarzania. Przesłanie formularza kieruje zwalidowane dane dalej w proces.
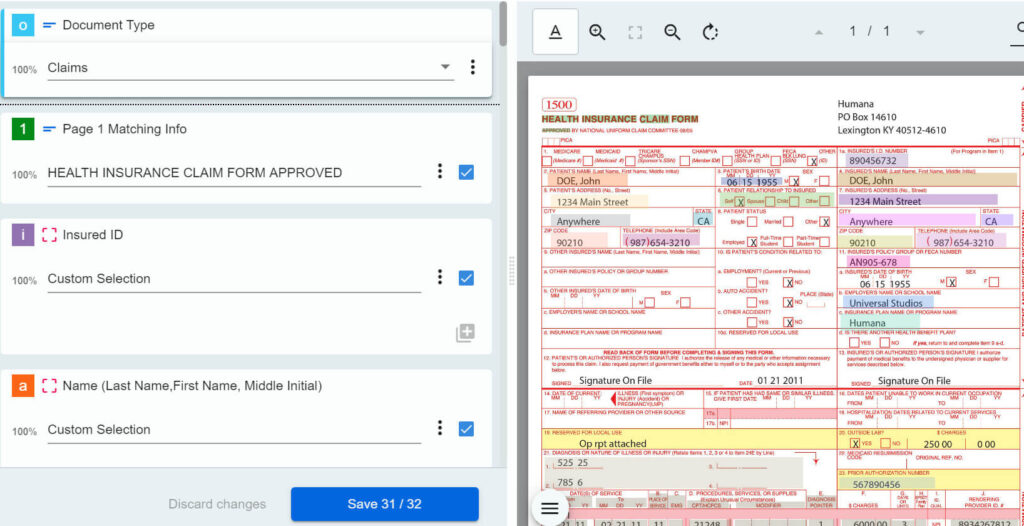
Poziom pewności to niezwykle przydatna funkcja, która pozwala nam kontrolować przepływ pracy w zależności od okoliczności przetwarzania i czynnika ryzyka. Jeszcze potężniejsze jest jednak połączenie go z walidacjami opartymi na regułach: jeśli jakiekolwiek wyodrębnione dane mają odpowiednik w naszych systemach, możemy porównać obie wartości i sterować przepływem w oparciu o ten rezultat.
Wytrenuj silikonowy mózg
Skoro włożyliśmy tyle pracy w przegląd klasyfikacji i walidację wyodrębnionych danych, byłoby szkoda tego nie wykorzystać. Niektóre frameworki, w tym UiPath Document Understanding™, oferują metodę przechwytywania zwalidowanych danych i ponownego użycia ich jako przykładów treningowych do dalszego szkolenia modelu. W ten sposób nasz model może z czasem się doskonalić.
Istnieje też inny etap, w którym chcemy lub nawet musimy wytrenować model. Gotowe pakiety działają całkiem dobrze, ale jeśli chcemy poprawić efektywność wstępnie wytrenowanej umiejętności, możemy od razu rozpocząć projekt od sesji etykietowania. To samo dotyczy niestandardowych typów dokumentów — to jak zaczynanie od zera, więc oprócz zdefiniowania konkretnej taksonomii musimy również wytrenować własny model.
Na szczęście dostarczanie modeli uczenia maszynowego przykładów jest niezwykle proste. Interfejs jest bardzo przyjazny dla użytkownika i sprowadza się do potwierdzania lub wybierania właściwych wartości na stronach zgodnie z naszą taksonomią. To jak kolorowanka typu point-and-click.
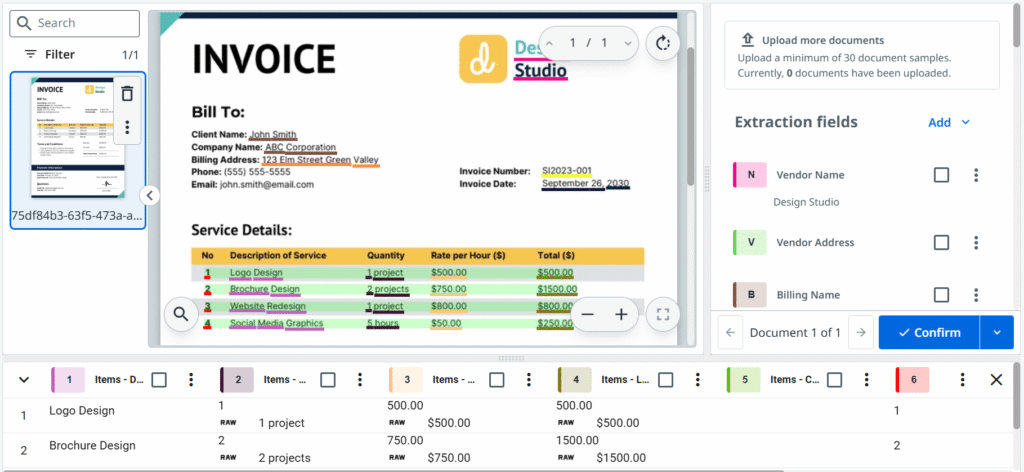
Wracając do wykorzystania informacji zwrotnej od człowieka, można osiągnąć w pełni automatyczną pętlę ponownego trenowania, ale istnieją co najmniej dwa zastrzeżenia. Po pierwsze, zakładamy, że dane wyjściowe z stacji walidacyjnej są rzeczywiście poprawne. Błędy podczas walidacji wyodrębnionych danych są mniej prawdopodobne, ale nadal możliwe. Po drugie, stacja walidacyjna wymaga potwierdzenia tylko jednej wartości, podczas gdy przykłady treningowe dostarczane do modelu muszą wskazywać wszystkie wystąpienia danego pola. W praktyce oznacza to, że jedynie dokumenty jednostronicowe można ponownie wykorzystać bez zmian jako przykłady treningowe.
Ogólnie rzecz biorąc, najlepszą praktyką jest zawsze przejrzenie próbki przed użyciem jej do treningu.
Główny cel
Dotarliśmy do szczęśliwego finału – przetwarzamy pliki o różnych strukturach dokumentów, klasyfikujemy wiele typów dokumentów oraz wyodrębniamy dane z walidacją i obsługą wyjątków. Wreszcie nadszedł czas, aby wykorzystać wyniki w docelowym procesie – w końcu cała ta droga miała prowadzić do tego, by faktycznie coś zrobić z ogromną liczbą otrzymywanych dokumentów.
W ramach UiPath Document Understanding™ niewiele pozostaje do zrobienia poza użyciem gotowych aktywności, które podają nam dane na tacy. Dla tych, którzy chcieliby korzystać z modeli Document Understanding™, ale budować resztę rozwiązania w innej technologii, dostępne jest przyjazne API (więcej w dokumentacji UiPath). Klasyfikacja i ekstrakcja danych obejmują większość scenariuszy przetwarzania dokumentów, jakie można znaleźć w operacjach biznesowych w dowolnej organizacji: kiedy się nad tym zastanowić, te dwie funkcje to wszystko, czego potrzebujesz.
Przetwarzanie faktur to tylko jeden przykład pojedynczego przepływu pracy, w którym cyfrowy papier jest jedynie niefortunnym nośnikiem informacji, które muszą zostać przeniesione pomiędzy dwoma systemami. Narzędzia takie jak UiPath Document Understanding™ świetnie radzą sobie z problemem automatyzacji, która obejmuje dane uwięzione w plikach PDF lub skanach.
Gdyby tylko udało nam się znaleźć alternatywę dla przesyłania sobie takich plików.
Och, czekaj…




